AWS
| Acronym |
Meaning |
Description |
| VPC |
Amazon Virtual Private Cloud |
Service to create Networks in AWS |
| EC2 |
Amazon Elastic Compute Cloud |
Service to create VM instances in AWS |
| IAM |
Amazon Identify and Access Management |
Services that manages login credentials and permissions (actions user can perform) to the AWS account |
| SSO |
AWS Single Sign-On SSO |
An AWS service identity provider (IdP) |
| AMI |
Amazon Machine Image |
OS image used to boot up VMs in EC2 |
| ECS |
Amazon Elastic Container Service |
AWS Service that provides containers orchestration using EC2 |
| ELS |
Amazon Elastic Kubernetes Service |
AWS Service that provides containers orchestration using Kubernetes |
| ACL |
Access Control Lists |
Lists that controls inbound and outbound traffic at the subnet level (everything is allowed by default) |
| RDS |
Amazon Relational Database Service |
|
| S3 |
Amazon Simple Storage Service |
Service that allows to access storage and data through URLs |
| ELB |
Elastic Load Balancer |
Amazon Elastic Load Balancer service |
| EBS |
Amazon Elastic Block Store |
External Persistent storage for EC2 instances, that can be seen as external drives to store data |
| EFS |
Amazon Elastic File System |
AWS services that provides file storage that can mount on to multiple EC2 instances |
| SNS |
Amazon Simple Notification Service |
AWS service that allows you to create a topic and then send out messages to subscribers of this topic |
What is Cloud Computing? & What is AWS?
Cloud computing is the on-demand delivery of IT resources over the Internet with pay-as-you-go pricing.
AWS (Amazon Web Services): Provides a collection of cloud computing services accessed via Internet to run SW applications. It provides compute, storage, database, analytics and machine learning services. AWS is a programmable data center
Everything you would want to do with a data center you can do with AWS so you rent these services
Main Advantages of cloud computing:
- Cost / Pay as you go Pay only for the computing resources you use instead of investing in servers and HW, avoid maintaining data centers
- Scalability It can be more easily scaled to deal with traffic increase and avoid sitting on expensive idle resources or dealing with limited capacity
- Speed and Agility Resources can be managed easily through a web app or API instead of dealing with HW & SW setups
- Global Availability Deploy you app in multiple regions around the world for lower latency and a better experience for your customers in other regions
- QA One of the main advantages of cloud computing is the ability to test a new feature of your application on a pre-production environment (on-premises), which is just a copy of the environment where your application runs in production
AWS API
- It what we use to logically manage your cloud infrastructure
- Allows you to programmatically provision, configure and arrange the interaction between your resources
- Its the only way external users interact with the AWS services and resources. For example: create a database
- Sits on top of the AWS infrastructure
- Ways to interact with AWS API:
- AWS Management Console:
- Web-based console/app that you can access from your browser, you can use GUI style prompts to setup AWS services
- You select the region on the top right, this directs your browser to make requests to the selected region (Identified by URL)
- Good for basic setup but prone to human error
- AWS Command Line Interface (AWS CLI):
- Tool/App you download and install on your machine to use the terminal to create and configure AWS services
- You create commands using a defined AWS syntax (Canonical command format:
aws <service_name> <service_specific_command> <command_configurations>)
- AWS Software Development Kits (AWS SDK):
- Software created and maintained by AWS for the most popular programming languages (Python, Java, .NET, etc.)
- Useful when you want to integrate your application source code with AWS services. In other words maintain same repo with app source code and AWS setup and configuration scripts
AWS Global Infrastructure
Amazon CloudWatch: Service that allows you to monitor an application or solution
Load balancer: service that allows you to distribute traffics across multiple instances of your application
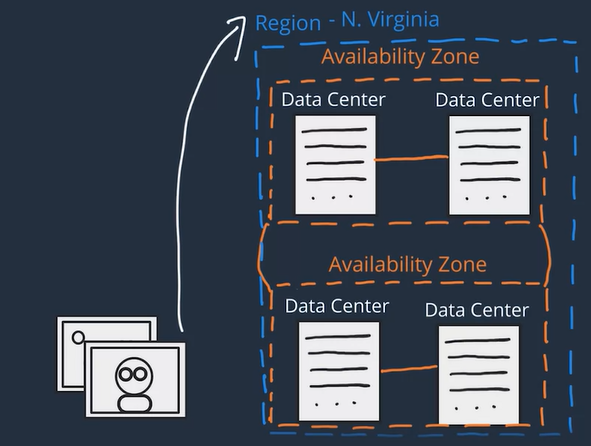
- Depending on the AWS Service you use, your resources are either deployed at the AZ, Region, or Global level.
Security on AWS
- Shared Responsibility Model (SRM) Security is a shared responsibility between AWS and AWS users
- AWS responsibility: security OF the cloud
- The physical servers and HW where your app is running
- The software services used by your application up through the virtualization layer.
- For example: DB and networking services, the host OS updates where the VMs your app will run (updates and patches on the Hypervisor not on the VMs), etc
- User responsibility: security IN the cloud
- User is responsible for properly configuring the service and your applications, as well as ensuring your data is secure.
- You are the one responsible of ensuring your data is encrypted secure and has proper access controls in place
- For example patching and updates on your VMs, encrypting user data in transit and at rest, control who can access the resources of your application
- AWS offer native (optional) features that can be enabled to achieve secure solution (Up to user to use and configure them). This means some services require you to perform all the necessary security configuration and management tasks, while other more abstracted services require you to only manage the data and control access to your resource
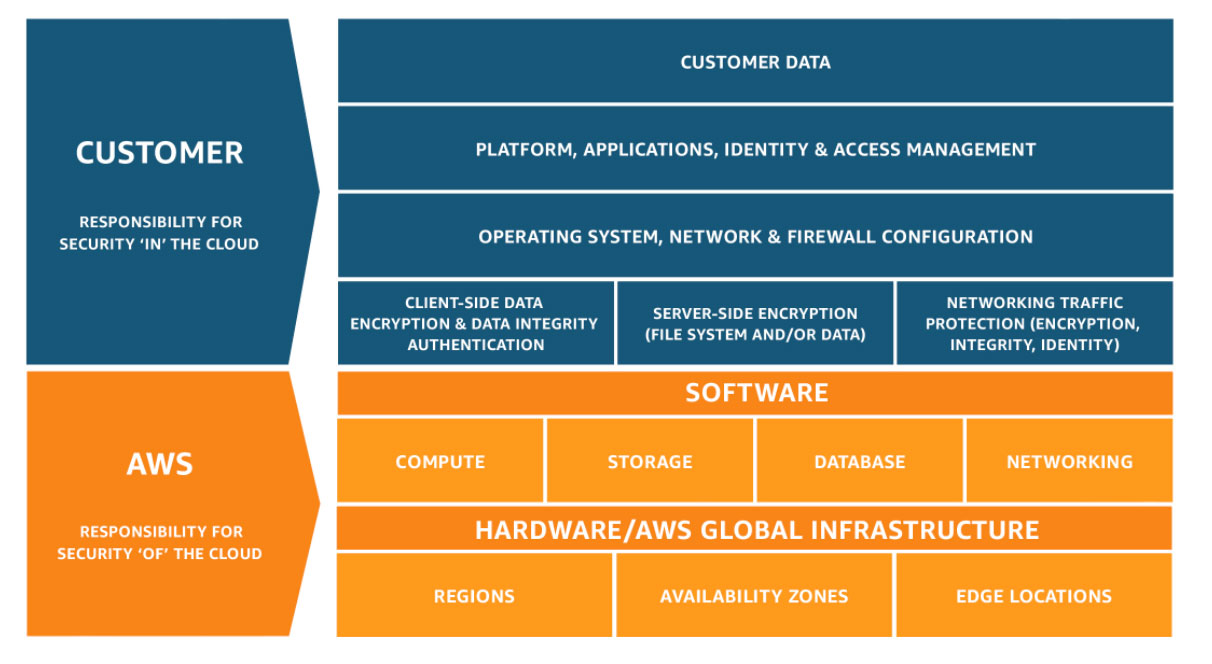
The Shared Responsibility Model can vary from service to service because each AWS service is different
Authentication ("Are you who you say you are?"): verify your identity, ensures that the user is who they say they are
Authorization ("What actions can you perform?"): is the process of giving users permission to access certain resources and services, determines whether the user can perform an action (like read, edit, delete, or create resources)
AWS Root User: The email address you used to sign-up on AWS becomes the root user
- This user has unrestricted access to everything in your account so you need to make sure no one can gain access to this root user
- The AWS root user has two sets of credentials associated with it: 1) email & password 2) access key ID & secret access key, (used for CLI and AWS API)
- Root User Recommendations:
- Enable Multi-Factor Auth. (MFA) for the root user
- Do NOT use the root user for everyday tasks
- Delete access keys: go to My Security Credentials page, Open the Access keys section and under actions click Delete and Yes
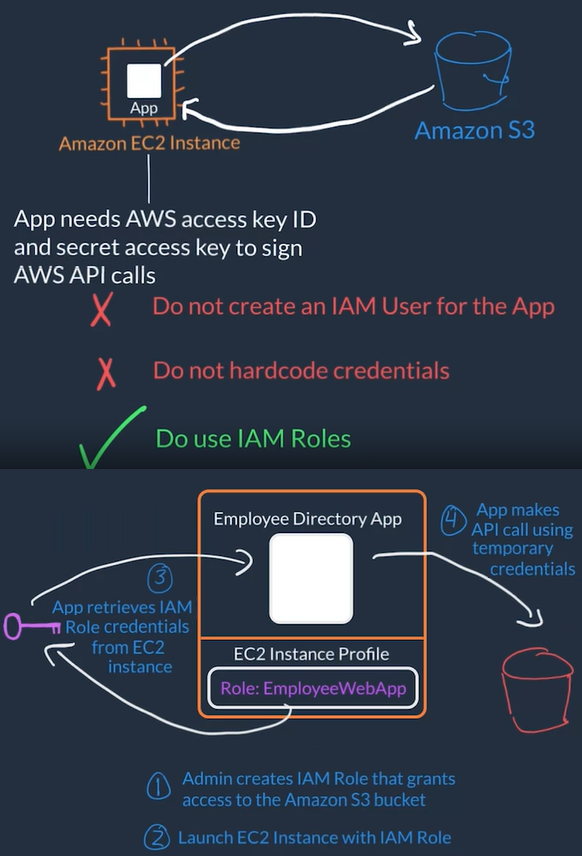
AWS Identity and Access Management (IAM)
Used to manage Authentication and Authorization on AWS for multiple people who needs access to your (root) AWS account
IAM is not responsible for the application level access management, this means it is NOT responsible for things like authenticating users into the application itself
AWS Account access management:
- AWS IAM manages the login credentials and permissions (actions user can perform) to the AWS account itself
- Allows to have unique credentials for each person logging in with certain permissions and privileges
- Each person who needs access to your AWS account would have an unique AIM user)
AWS Policies
- Policies attach to IAM users, IAM groups of users or IAM Roles to grant/deny permissions to take actions
- AWS Actions = AWS API calls: every action is AWS is an API call
- The policies are the ones that manage the credentials used to sign API calls made to AWS services.
- Defined in JSON-based files:
- Effect: allow or Deny
- Action: Comma separated list of actions (API calls), for example: "ec2:*" (Allow all actions), "ec2:RunInstances" (Allow only to run instances)
- Resource: Restrict which AWS resources the actions are allowed to performed against
- Conditions:: Conditions to further restrict actions
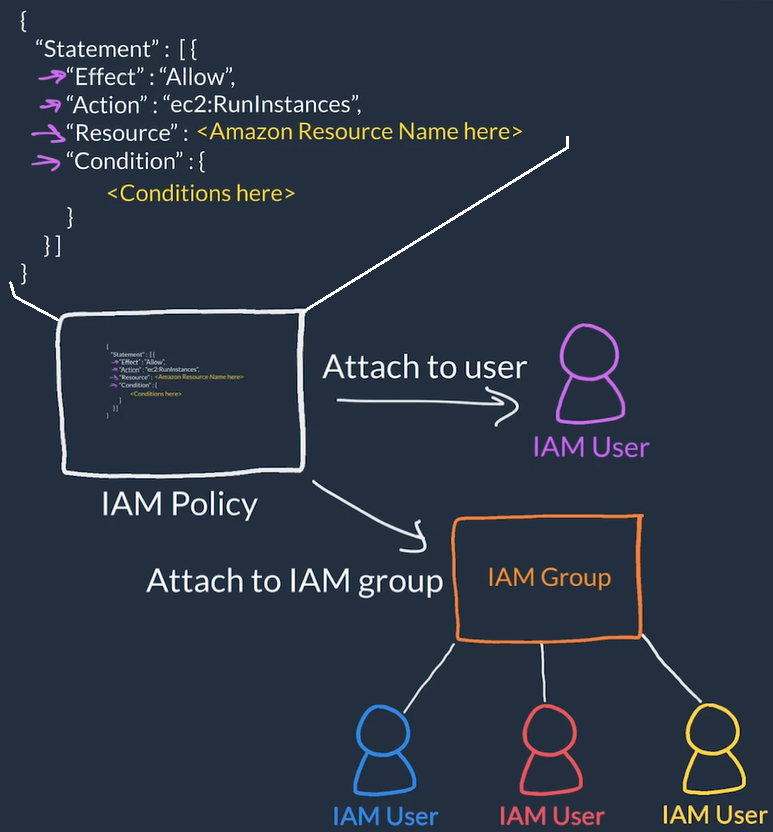
User Root user to create IAM user with administrator permissions and use this user to create IAM groups, users and policies for the rest of the people and always attach policies to groups then add users to groups instead of managing policies and permissions at the user level
AWS Compute
- At a fundamental level, there are three types of compute options: virtual machines, container services, and serverless
Amazon EC2
- Elastic Compute Cloud (EC2) is a web service that provides secure resizable compute capacity in the cloud. In summary EC2 allows you to create virtual machines to host applications
- An EC2 instance is a single virtual machine that has resources (VCPU, RAM, storage, network capacity...) which runs on an actual AWS server (or host), a hypervisor manages/mediates these instances (virtual machines)
- EC2 is the compute service that gives you flexibility because it allows you control and configure instances to meet your needs
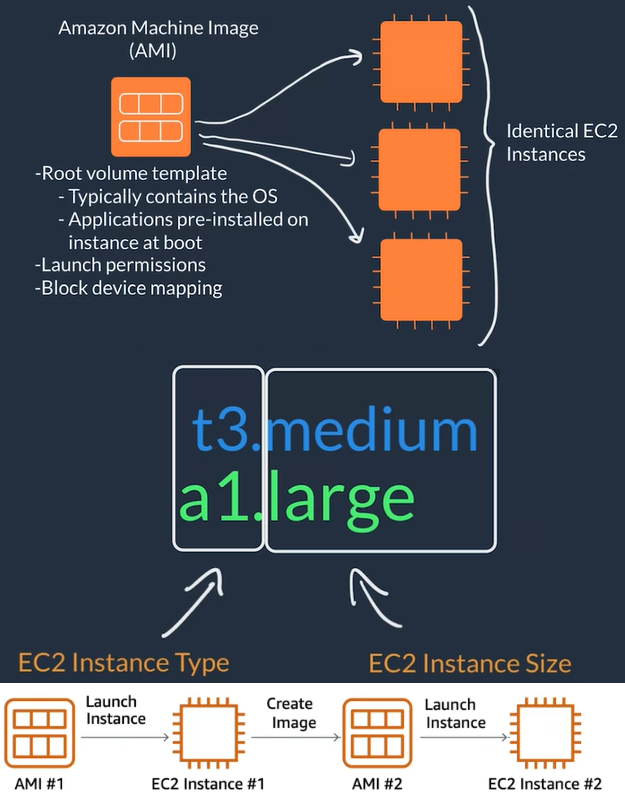
- AWS uses Amazon Machine Images (AMI) to select the operating system for our VMs and these AMIs are grouped for use cases (Compute optimized, memory optimized, storage optimized, graphics intensive, etc)
- AWS allows you to create an AMI from your running instance and use this AMI to start a new instance
- You can create more EC2 Instances depending on your application demands and the size of your user base.
EC2 Availability and Network
Compute instances need to exist inside of a network and in AWS these networks are called VPC
By default, EC2 instances are placed in the default Amazon Virtual Private Cloud VPC and any resource you put inside the default VPC will be public and accessible by the Internet (so you shouldn’t place any customer data or private information inside of it). To change this you will need to setup and configure your own VPC that meets your needs
Inside the selected VPC network, your instance resides in an Availability Zone of your choice so when architecting any application for high availability, consider using at least two EC2 instances in two separate Availability Zones
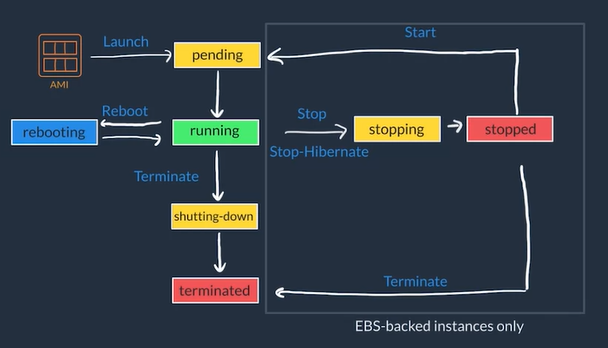
EC2 Instance Lifecycle
- You Launch EC2 Instance from AMI
- Pending state which means VM is booting up
- When an instance is ready to run it enters Running state
- You can Reboot an instance, this makes it transition to the Rebooting state to restart the instance
- You can Stop (powers OFF the VM, which means instance will get new public IP but maintaining private IP when powered back ON) or Stop-Hibernate (this stops VM it but saves state), this transitions the instance to Stopping State and the to Stopped
- From Stopped State you can Start your VM to turn it back ON which will go through normal boot sequence (Pending -> Running)
- You can Terminate you VM transition to the Terminated state going through the Shutting-down state if the instance was running
- Instances that are terminated remain visible for some time but all the data is deleted forever on a terminated instance and lose both the public IP address and private IP address of the machine.
EC2 Pricing Options
In general You get charge for instances in Running state
- On-Demand:
- Pay for compute capacity with no long-term commitments
- Billing begins whenever the instance is running, and billing stops when the instance is in a stopped or terminated state.
- The price per second is fixed
- Reserve Capacity with Reserved Instances (RIs)
- RIs provide a discounted hourly rate and an optional capacity reservation for EC2 instances
- You can pay Upfront (Cheapest), Partial Upfront (Cheaper), or No Upfront (Cheap) and select 1-year or 3-year term
- Spot Instances
- Available at up to a 90% discount compared to On-Demand prices.
- Set a limit on how much you would like to pay for the instance hour, AWS determines if what you pay is enough to run an instance based on current demand, if it is AWS will give you an instance but it will interrupt your instance in case conditions change
How to setup an EC2 Instance Example
- To launch an EC2 instance we need to setup:
- The AMI: OS image like an AWS optimized Linux, Ubuntu, Windows, MacOS...
- The instance type or HW profile: Blend of resources CPUs, Graphics Card, RAM, network capabilities...
- The instance size: Determines how much of the HW selected on the type the instance will have
- Security groups: Services TCP/HTTP
- Storage: non-volatile storage size
- Key pairs
- EC2 Setup steps
- Go to on AWS management console go to EC2
- Click on Launch Instance
- Select Free Tier Linux AMI option and T2 Micro Type
- Select default VPC
- Usually select a previously created IAM role
- Setup User Data with a script that will run when instance boots up
- Select storage (usually defaults)
- Add tag with key-value:
Name:<APP-NAME>-webapp
- Select Create new security group
- Make sure you have 3 rows 1) SSH - TCP - 22 - Custom ; 2) HTTP - TCP - 80 - Anywhere 3) HTTPS - TCP - 80 - Anywhere
- Port 80 should be open if the instance is a web server but not if it's an internal server or database server
- Click Review and launch and Launch button again
- Acknowledge the checkbox for the private key and click Launch Instances
- Usually takes some minutes for the instance to be created and boot
- Go to EC2 -> Instances select the instance and find the Public IPv4 Address field for access
Create EC2 Instance Lab
Container Services on AWS
Containers
- Containers provide portability
- Containers have shorter boot up time so fast response to increasing demand, containers is the option
- A container is a standardized unit that packages up your code and all of its dependencies.
- Container creates its own independent environment which is designed to run reliably on any platform
- While containers can provide speed, virtual machines offer you the full strength of an operating system and offer more resources, like package installation, a dedicated kernel, and more.
- Dockers is a container runtime that allows you to create, package, deploy, and run containers.
- Using containers makes it easier to support micro-services or service-oriented designs.
AWS Containers Orchestration Services
- AWS provides containers orchestration services like: ECS & EKS
- Amazon Elastic Container Service (ECS )
- It is an end-to-end container orchestration service that allows you to quickly spin up new containers and manage them across a cluster of EC2 instances.
- To use it you need to install Amazon ECS Container Agent on your EC2 instances to perform actions like launching and stopping containers, getting cluster state, scaling in and out, scheduling the placement of containers across your cluster, assigning permissions
- Container instance: An instance with the container agent installed
- Amazon ECS uses a task definition which is a text file, in JSON format, that describes one or more containers and the resources you need to run that container,
- A Container is called a task
- Amazon Elastic Kubernetes Service (EKS )
- Kubernetes is a portable, extensible, open source platform for managing containerized workloads and services.
- Kubernetes philosophy is to bring software development and operations together by design
- In Amazon EKS, the agent is called a worker node
- A Container is called a pod.
- When we use containers we need processes for starting, stopping, restarting, monitoring containers which run on multiple EC2 instances (EC2 Cluster), this is called containers orchestration, doing this manually is not viable/scalable
- On AWS containers orchestration services user makes API calls to manage the service and the orchestration carries out the management tasks on the EC2 cluster
- You can automate the scaling of the cluster and scaling of the containers
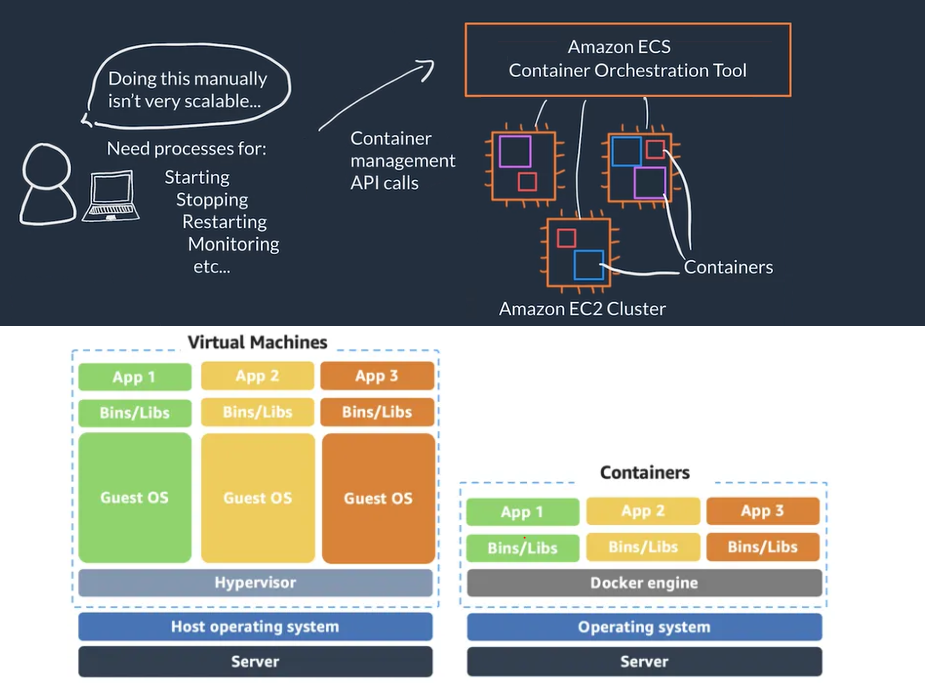
Serverless
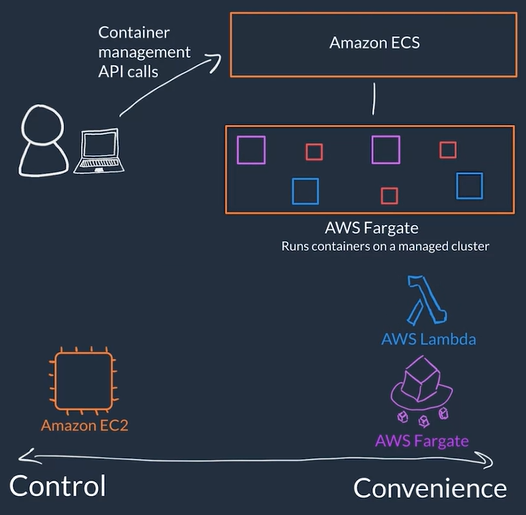
- Serverless You can not access the underlying infrastructure or instances that are hosting your solution, the management of the underlying environment is taken care for you
- When using serverless services you are NOT in charge of provision/setup, scaling, fault-tolerance and maintenance of the environment, this is abstracted form you
- AWS Fargate is a serverless compute platform for ECS or EKS: you run your containers on a managed serverless compute platform
- You define your container how you want your container to be run, then it scales on-demand
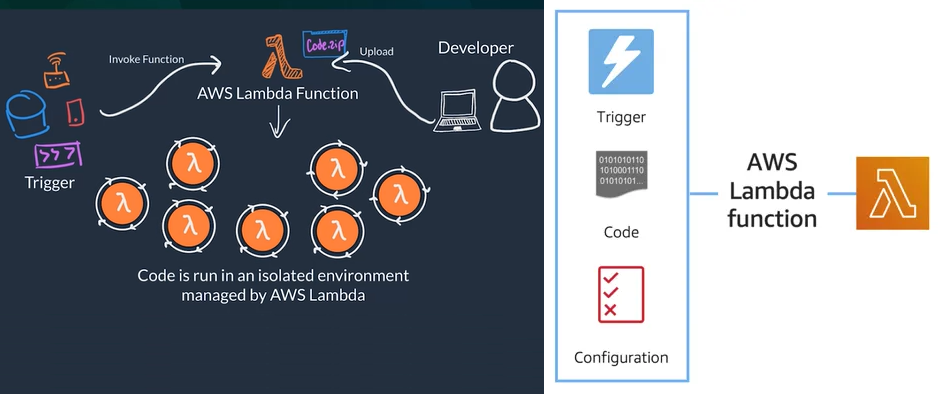
AWS Lambda
- AWS Lambda is a serverless compute service, General flow
- Code: (What) You package and upload your code to the lambda services, this creates a Lambda Function (Not running all the time)
- Configuration: (How) Configure a trigger which is the one that kicks-off the execution of the lambda function and other setup that describes how the function should run, like: network placement, environment variables, memory, invocation type, permission sets, etc.
- Examples of triggers: HTTP request, upload of a file to the storage service S3, other events originating from other AWS services
- Trigger: (When) When trigger is detected the code of the Lambda Function runs is an isolated environment managed by AWS Lambda Service
- You can have many triggers and AWS Lambda scale your function to meet demand each running in a secure and isolated env.
- Designed to run code with runtime <= 15 minutes
- Suited for quick processing, like a web backend for handling requests or a backend report processing service.
- The AWS Lambda function handler is the method in your function code that processes events. When your function is invoked, Lambda runs the handler method
def lambda_handler(event, context):
...
return some_value
- When selecting a handler the default is
lambda_function.lambda_handler
lambda_handler the function namelambda_function the file where the handler code is stored in lambda_function.py
You charged for the number of times your code is triggered (requests) and for the time your code executes, rounded up to the nearest 1ms (duration). This is the reason AWS lambda is recommended for functions with low execution time (under 100ms) or for low latency APIs.
AWS Networking
- How you configure the network is what makes it enables Internet traffic to flow into your application.
- Classless Inter-Domain Routing (CIDR) notation: used to express IP addresses between a certain range (i.e.
192.168.1.0/24) the number /N at the end specifies how many of the bits are fixed of values the rest are flexible (i.e 192.168.1.0/24 means the first 24 bits = 3 octets are fixed and the last byte=octet is flexible which means the range is from 192.168.1.0 to 192.168.1.255)
- The higher the number after the `/``, the smaller the number of IP addresses in your network
- In the AWS Cloud, you choose your network size by using CIDR
- Smallest IP range is
/28, which provides you 16 IP addresses
- Largest IP range is
/16, which provides you with 65,536 IP addresses.
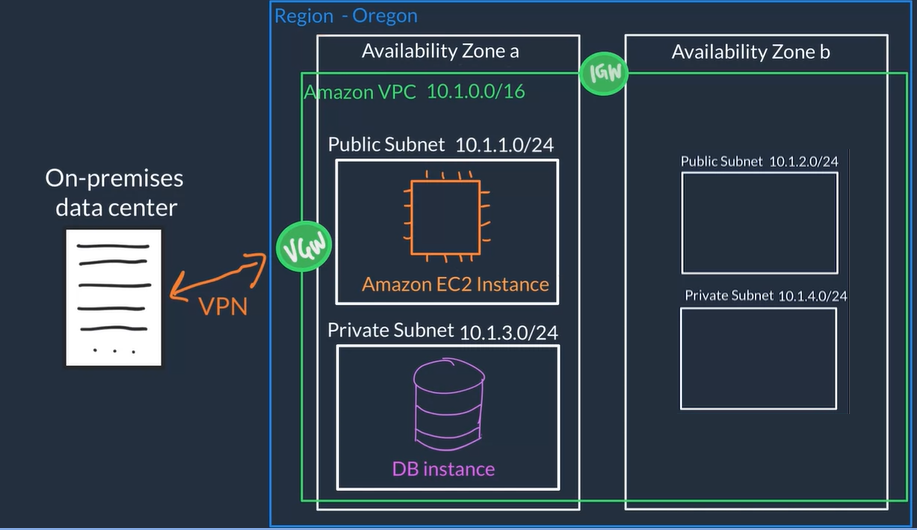
Amazon VPC
Virtual Private Cloud (VPC) a private network for you AWS resources
A VPC creates a boundary where your applications and resources are isolated, So nothing comes into or out of the VPC without your explicit permission
Virtual Private Cloud, allows to run an isolated network connected to the Internet or private networks
Allows us to define how network traffic flows between the sub-nets and out to the Internet, we use Internet gateways and rules to route the traffic from the web-server sub-net to the Internet gateway, rules are stored in route tables for this
Allows to securely connect Web servers for example connecting the main web server where our application lives to a database server
Creation of a VPC general flow
- Specify basic info:
- Name Just an identifier for your VPC
- Region The region where you VPC and app will live
- IP Range / CIDR i.e
10.1.0.0/16
- Divide space inside the VPC into subnets which are smaller segments or virtual area networks (VLANs) which provide a more granular controls over access to your resources.
- Use case examples of subnets:
- We put EC2 instances (this is the resources in this case) inside of these subnets
- If we have public resources that we want to be publicly accessed over the Internet, we put those resources on a subnet with Internet connectivity
- For private resources like a DB we can create another subnet with different controls to keep the DB private
- Create subnets and specify basic info: 0) subnet Name, 1) VPC, 2) AZ , 3) IP Range / CIDR (subset of VPC IP range)
- Create an Gateway: just need to specify a Gateway Name* and once it is created you can attach it to a VPC
- Internet Gateway (IGN) for traffic that needs Internet connectivity
- Virtual Private Gateway (VGW) to allow only certain traffic and don't allow direct access from the Internet, this type of gateway allows you to establish an encrypted VPN connection to your private internal AWS resources
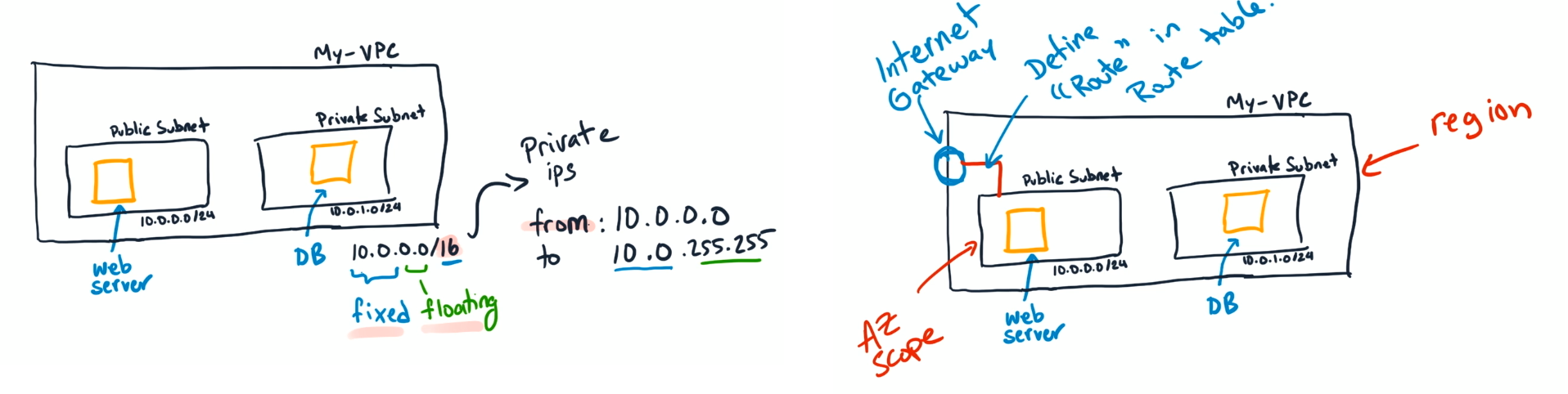
- AWS reserves five IP addresses in each subnet you create. These IP addresses are used for routing, Domain Name System (DNS), and network management.

VPC Routing
- Route tables contains a set of rules, called routes, that are used to determine where network traffic is directed.
- Route Tables have destination and target
- The destination, which is a range of IP addresses where you want your traffic to go (IP range of our VPC network)
- The target, which is the connection through which to send the traffic (i.e. through the local VPC network.)
- When you create a VPC, AWS creates the Main Route Table and applies it to the entire VPC
- The default configuration of the main route table is to allow traffic between all subnets local to the VPC.
- Whether a subnet has access to the public Internet or not depends on its associated route table
- so you 1) create a route table, 2) give it rules that define which traffic it will accept and then 3) associate it with a subnet
0.0.0.0/0 means it can take and deliver traffic from anywhere
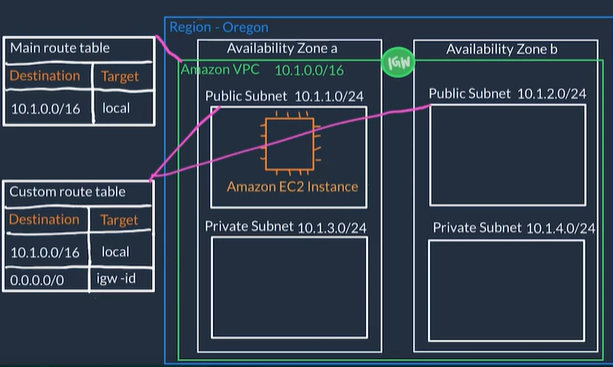
VPC Security
- In AWS, you have two options to secure your VPC resources
- Network Access Control Lists (network ACLs) (everything is allowed by default so you can both allow and deny rules.):
- Firewall at the subnet level
- Defines Rules that control what type of traffic is allowed to enter (inbound) and leave (outbound) the subnet, for example only HTTPS
- The default network ACL allows all traffic in and out of your subnet.
- Security Groups (everything is blocked by default so you allow rules)
- Firewall at the EC2 instances level
- EC2 instances must be placed inside a security group that allows the appropriate kinds of traffic to flow to your application
- The default configuration of a security group blocks all inbound traffic and allows all outbound traffic, so when creating security groups we usually open up inbound ports
Security groups and network ACLs are powerful tools to filter network-wide traffic for a single instance or subnet traffic.
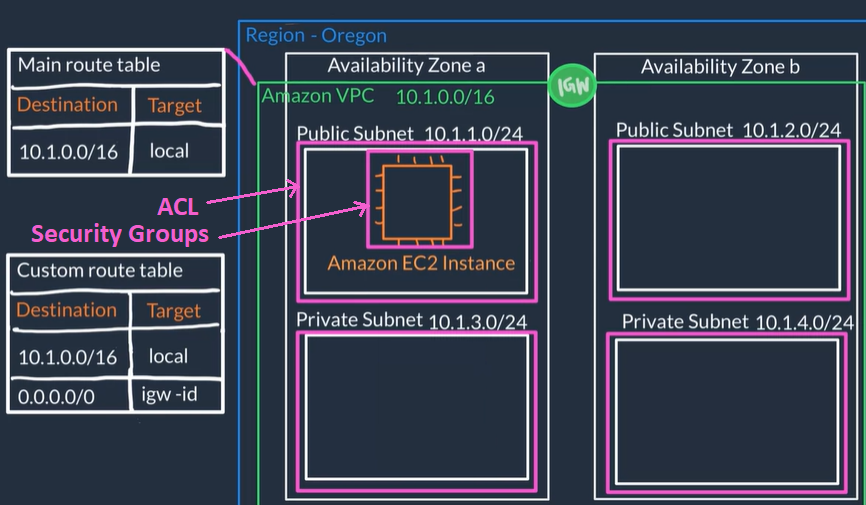
- We use CloudFormation and VPC to build networks.
- A stack
- it is a set of resources that CloudFormation will manage for us
- it is an instance of a template
- ssh -i ~/.ssh/pepekeypair.pem ec2-user@54.245.47.33
- Public IP: 54.245.47.33 VPC ID : vpc-137a036a edx-subnet-public-a: subnet-6ff75416
Storage on AWS
Choose the Right AWS Storage Service
Storage Concepts
- File Storage
- Files live in a tree-like hierarchy that consists of folders and sub-folders.
- Files have metadata such as file name, file size, the date the file was created, etc.
- File have a path used to find it in the file hierarchy and retrieve
- File storage treats files as a singular unit
- File storage systems are often supported with a network attached storage (NAS)
- Block Storage:
- File is split into fixed size blocks of data and then stored.
- Blocks have their own addresses, this means block are addressable and can be retrieved efficiently
- Only Address is needed No additional metadata associated with each block
- When data is requested, addresses are used to organize the blocks in the correct order to form a complete file to present back to the requester
- Used for more frequently updated data
- Updates are cheaper in terms of computational power because you only need to update the chunk that requires change(s)
- Fast and use less bandwidth.
- Block storage in the cloud is analogous to direct-attached storage (DAS) or a storage area network (SAN)
- Object Storage:
- Treats each file like a single unit of data, called objects.
- Each object is a file with a unique ID
- Unique ID and metadata is bundled with the data and stored
- An object is simply a file combined with metadata that has a unique ID
- Object are stored in a flat structure instead of a hierarchy
- Used for WORM (Write Once, Read Many) data or data that is not frequently updated
- Updates cost more in terms of computational power because you need to update the entire file even if changes are only to certain parts
- Used when storing large data sets, unstructured files like media assets, and static assets, such as photos.

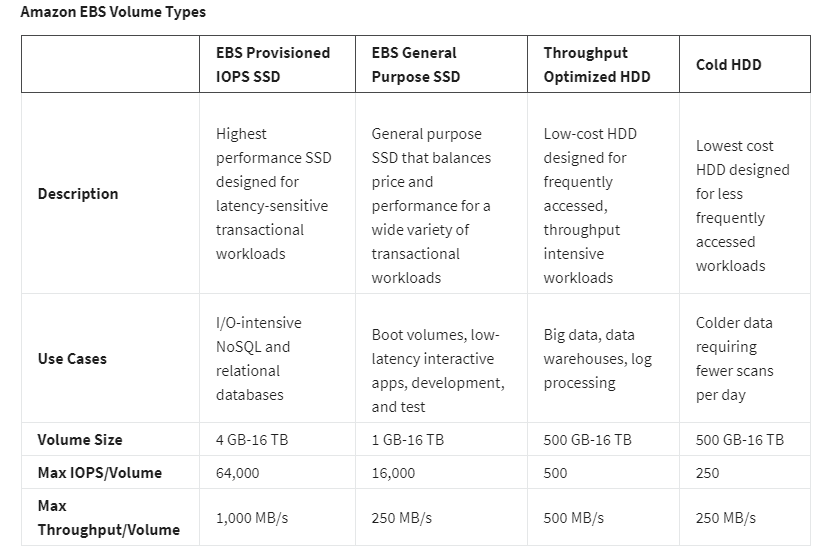
Block Storage in AWS (EC2 Instance Storage & EBS)
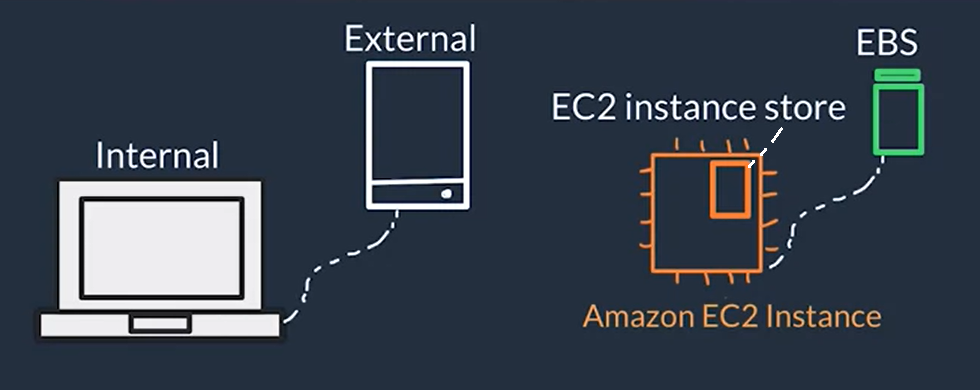
Object Storage in AWS (S3)
- Amazon Simple Storage Service (Amazon S3) or Storage for the Internet
- S3 is a standalone storage solution that isn't tied to compute
- You don't mount this type of storage onto your EC2 instances. Instead, you can access your data through URLs from anywhere on the web (but not by anyone)
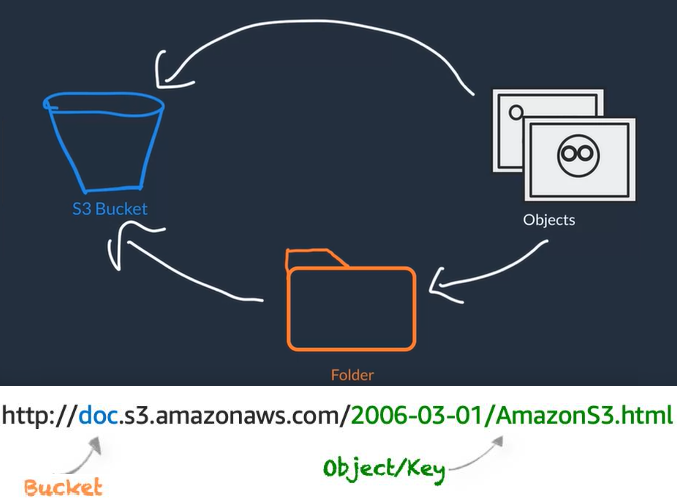
- Allows you to store as many objects as you'd like with an individual object size limit of 5TB
- object name = key name
- It is a distributed storage service because AWS stores your data across multiple different facilities within one AWS region
- You store your objects in buckets so you need to first create buckets (buckets are region specific so we want to place them close to our infrastructure for our app)
- You can have Folders inside buckets to organize your objects
- Everything in S3 is private by default so objects can only be viewed by the user or AWS account that created that resource (with the appropriate keys) but you can also make objects public to anyone or control access using IAM policies and bucket policies
- S3 bucket policies policies attached to buckets that specify what actions are allowed or not on the bucket (E.x. allows another AWS account to put objects in a bucket but not delete them, or allow only read-only to objects in a bucket)
- S3 common use cases: Media hosting like video, photo, or music, SW applications that customers can download, static websites (HTML + CSS + client-side Scripts)
- S3 versioning: Enables you to keep multiple versions of a single object in the same bucket. o recover from accidental deletions, accidental overwrites or application failures
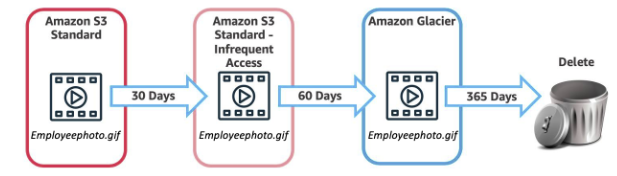
- Object uploaded to S3 must have a storage class:
- Amazon S3 Standard default storage class considered for general purpose storage
- Amazon S3 Intelligent-Tiering used for unknown or changing access patterns, AWS automatically your moves data to a frequent access tier and an infrequent access tier based on frequency access (each tier has different cost)
- Amazon S3 Standard-Infrequent Access (S3 Standard-IA) For data that is accessed less frequently, but requires rapid access when needed, ideal if you want to store long-term backups, disaster recovery files, and so on.
- Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) Stores data in a single AZ and costs 20% less than S3 Standard-IA. used for data that does not require availability and resilience
- Amazon S3 Glacier low-cost storage class used for data archiving, retrieval options range from a few minutes to hours.
- Amazon S3 Glacier Deep Archive Used for data that may be accessed once or twice in a year, for archives that need to be retained for several years to meet regulatory compliance
Automate Tier Transitions with Object Lifecycle Management
- Using a lifecycle policy allows you to automatically change your data from storage tier to storage tier, to do this you can define the following actions on the policy
- Transition actions are used to define when you should transition your objects to another storage class.
- Expiration actions define when objects expire and should be permanently deleted.
File Storage in AWS (EFS: Amazon Elastic File System)
- EFS is used for file storage that can mount on to multiple EC2 instances
- You don’t have to provision storage in advance so you only pay for what you use
- Amazon Elastic File System (EFS): Fully managed NFS file system.
- Amazon FSx for Lustre: Fully managed Lustre file system that integrates with S3.
- Amazon FSx for Windows File Server: Fully managed file server built on Windows Server that supports the SMB protocol.
Databases Concepts
Relational databases
- A Relational Databases organizes data into tables
- Data in one table (rows & columns) can be linked to data in other tables to create relationships
- A row (or record) contains all information about a specific entry. Columns describe attributes of that entry.
- Logical schema: Refers to the tables, rows, columns, and relationships between tables in a DB
- A relational database management system (RDBMS)
- It is a system that allows you to create, update, and administer a relational database.
- Examples of RDBMS: MySQL, SQL server, PostgresQL, etc.
- You interact with most RDBMS by using Structured Query Language (SQL) queries (i.e.
SELECT * FROM table_name)
- Advantaged of Relational Databases:
- Joins: You can join tables to query relationships between data
- Reduced redundancy: You can store data in one table and just reference it from other tables (not storing the actual data)
- Accuracy: Use the ACID (atomicity, consistency, isolation, durability) principle to ensure that your data is persisted with high integrity
Non-Relational databases
- Non-relational databases have flexible schemas
- The types of queries you run on non-relational databases tend to be simpler, and focus on a collection of items from one table, not queries that span multiple tables
Databases on AWS
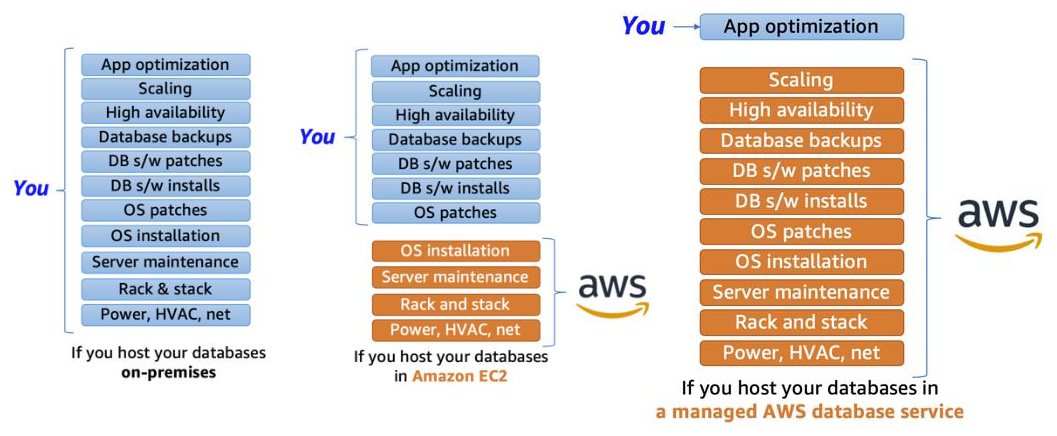
You can host a DB on EC2 instance (a.k.a unmanaged database) in this case you are still responsible for: DB engine setup, Updating DB SW, DB Backups and setup across multiple availability zones
You can use AWS RDS (Relational Database Service) that allows you create and maintenance of the DB but you are not responsible of most of the DB setup (a.k.a Managed Database).It makes it easier for you to setup, operate, and scale a relational database
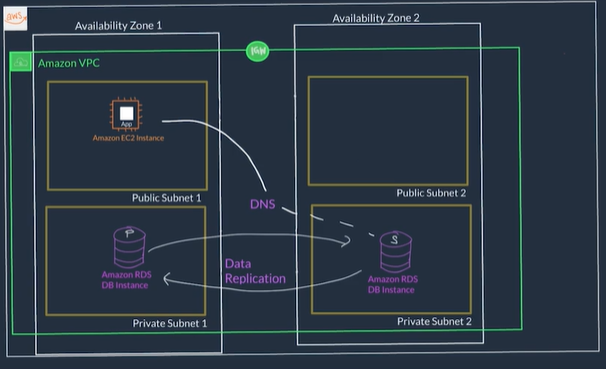
Amazon RDS
- Amazon RDS enables you to create and manage relational databases in the cloud
- When you create an RDS DB instance, it gets placed inside a subnet (which is bound to only an AZ) inside of a VPC (just like an EC2 instance)
- RDS can be configured to automatically launch a secondary DB instance in another subnet and therefore another AZ this is called RDS Multi-AZ Deployment
- When using RDS Multi-AZ Deployment, RDS manages all data replication so they stay in sync and also manages failures on the instances
- The app only needs to ensure reconnections to the database if it experiences a momentary outage
- With RDS Multi-AZ Deployment you end up with two Databases: a primary copy in a subnet in one AZ and a standby copy in a subnet in a second AZ.
RDS charges per hour of instance runtime,
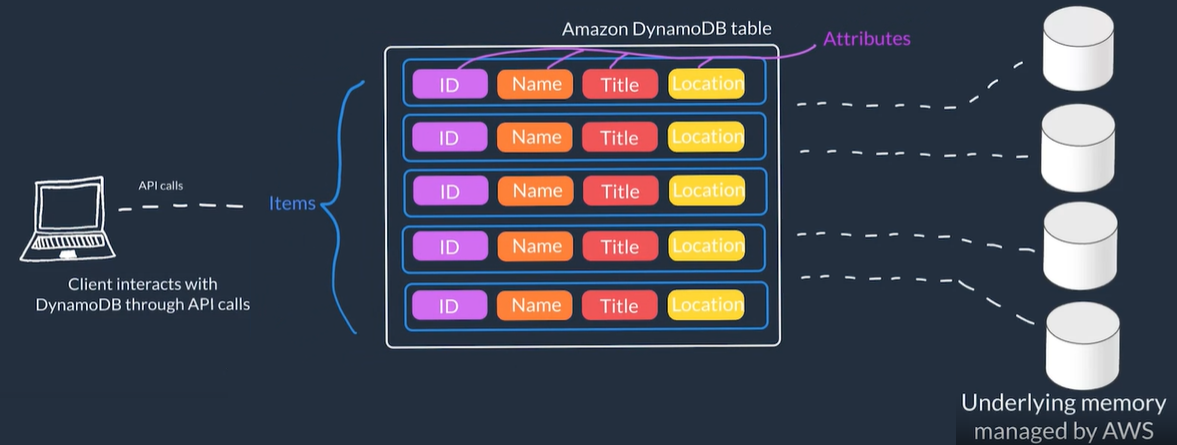
Amazon DynamoDB
- DynamoDB is a non-relational, serverless, key-value type database this means you don't need to manage or setup the underlying instances running the DB
- You don't create a database with tables that relate to each other you just create standalone tables.
- DynamoDB table is just a place where you can store and query your data.
- Data is organized into tables with items which have attributes.
- A table is a collection of items, and each item is a collection of attributes.
- You can add or remove attributes from items in the table at any time, and not every item in the table has to have the same attributes
- Primary keys are used to uniquely identify each item in a table and secondary indexes to provide more querying flexibility
- Core Components Components:
- Tables: In general data is stored in tables. A table is just a collection of data
- i.e. a People table that you could use to store personal contact information about people
- Items Each table contains zero or more items. An item is a group of attributes that is uniquely identifiable among all of the other items
- i.e. In a People table, each item represents a person
- Attributes Each item is composed of one or more attributes. An attribute is a fundamental data element, something that does not need to be broken down any further
- i.e. An item in a People table contains attributes called PersonID, LastName, FirstName, etc.
- DynamoDB manages the underlying storage:
- Scaling: increase and/or decrease size
- Redundancy: With copies across Availability Zones and mirrors the data across multiple drives
- Security: Offers encryption at rest to protect sensitive data
- General flow to use DynamoDB:
- Create a table, giving it Primary key / Partition key
- (Optional) Chose settings (Or use defaults)
- Wait for it 's status to be Active
Purpose Built Databases on AWS
| Database Type |
Use Cases |
AWS Service |
| Relational |
Traditional applications, ERP, CRM, e-commerce |
Amazon RDS, Amazon Aurora, Amazon Redshift |
| Key-value |
High-traffic web apps, e-commerce systems, gaming applications |
Amazon DynamoDB |
| In-memory |
Caching, session management, gaming leaderboards, geospatial applications |
Amazon ElastiCache for Memcached, Amazon ElastiCache for Redis |
| Document |
Content management, catalogs, user profiles |
Amazon DocumentDB (with MongoDB compatibility) |
| Wide column |
High-scale industrial apps for equipment maintenance, fleet management, and route optimization |
Amazon Keyspaces (for Apache Cassandra) |
| Graph |
For applications that require you to figuring out who is connected to who and querying that sort of data. Fraud detection, social networking, recommendation engines |
Amazon Neptune |
| Time series |
IoT applications, DevOps, industrial telemetry |
Amazon Timestream |
| Ledger |
For apps where you need to keep track of everything with assurances that nothing is lost, in other words an immutable ledger. Systems of record, supply chain, registrations, banking transactions |
Amazon QLDB |
Monitoring on AWS
Introduction to Monitoring
Metrics: Data points generated by the different AWS services
Statistics are metrics that are monitored over time
Metrics Statistics can then be used to establish a baseline, and this baseline can then be used to determine if things are operating smoothly, or not
- If the information collected deviates too far from the baseline, you would then trigger automatic alerts
- A good monitoring solution gathers data in one centralized location
Monitoring: The act of collecting, analyzing, and using data to make decisions about your IT resources. Benfits of monitoring:
- Respond to operational issues proactively before your end users are aware of them: keep tabs on metrics like error response that help signal that an outage is going to occur to perform actions to prevent the outage from happening
- Improve the performance and reliability of your resources: Identify bottlenecks and inefficient architectures to make improvements
- Recognize security threats and events: Spot anomalies like unusual traffic spikes or unusual IP addresses accessing your resources and take actions to investigate the event(s).
- Make data-driven decisions for your business: Collect application-level metrics and view the number of users using a new feature to decide whether to invest more time into improving this new feature
- Create more cost-effective solutions: View resources that are being underutilized and rightsize your resources to your usage
Amazon CloudWatch
AWS dedaults metrics
- AWS services report different metrics that are available for monitoring with CloudWatch for example CPU utilization for instance, Diks Read/Write operations, Network packets In/Out, etc.
Alarm example: Defining an alarm that will be triggered if 500-error responses go over a certain amount for a sustained time period and trigger an EC2 instance to be rebooted, so when we detect more five 500-error responses per hour the EC2 instance will be automatically rebooted
Basic monitoring Refers to AWS services sending metrics automatically for free to CloudWatch at a rate of one data point per metric per 5-minute interval
Detailed monitoring Refers to some AWS services posting metrics every minute instead of every 5 minutes, which has an extra fee associated.
High-resolution custom metrics enable you to collect custom metrics down to a 1-second resolution.
CloudWatch Logs
- Cloudwatch service that can monitor, store, and access your log files from applications running on Amazon EC2 instances, AWS Lambda functions, and other sources.
- Allows you to query and filter your log data
- You can set up metric filters on logs, which turn log data into numerical CloudWatch metrics that you graph and use on your dashboards.
- Some services are set up to send log data to CloudWatch Logs with minimal effort (like AWS Lambda) but others need configuration (like EC2 that needs to have the CloudWatch Logs agent installed and cofigured on the EC2 instance.)
- CloudWatch Logs Terminology:
- Log event: it has a timestamp and an event message of a record of activity recorded by the application
- Log stream: Sequences of log events that all belong to the same resource. For example logs for an EC2 instance
- Log groups: Composed of log streams that all share the same retention and permissions settings. For example, if you have multiple EC2 instances hosting your application you can group the log streams from each instance into one log group
Optimization on AWS
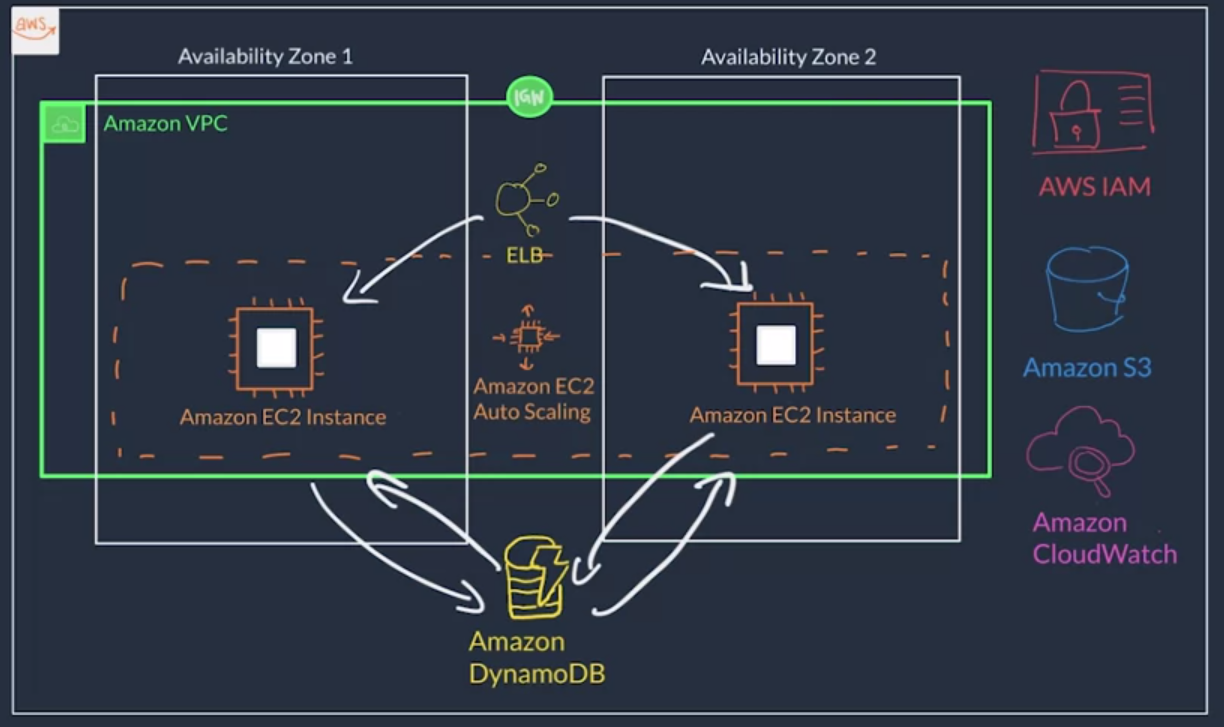
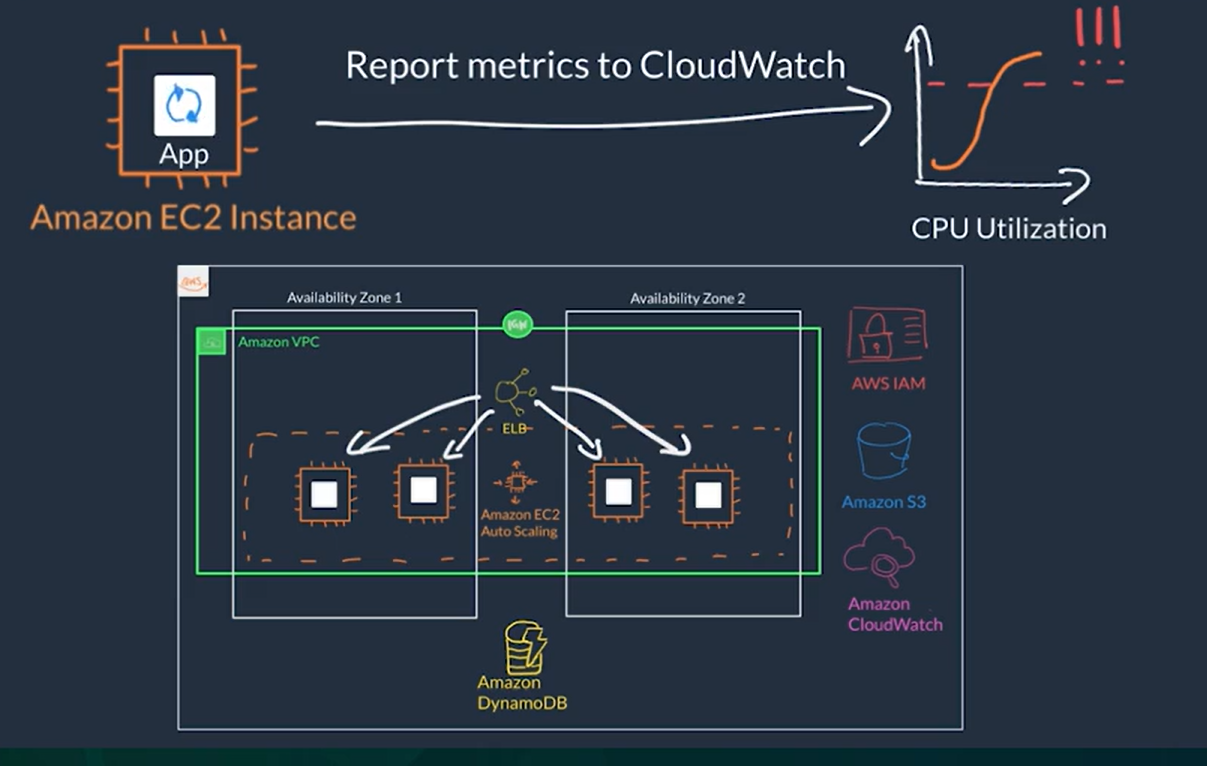
Amazon EC2 Auto Scaling
Increase vertically: Increase size of current instances
Increase Horizontally: Increase the number instances
The Availability of a system is typically expressed as a percentage of uptime, to increase availability, you need redundancy.
To hace redundancy you need to solved teh followign problems
- Manage replication: Create a process to replicate the configuration files, software patches, and application itself across instances.
- Address Customer Redirection Distributing the load across each server
- A load balancer distributes requests across a set of resources for you, this solves the problem of having multiple instances running your application where each instances has a different IP, you would have to route the questes to the different IPs manually
- High Availability: Define the type of availability you need
- Active-Passive: Only one of the two instances is available at a time, the other is a backup that goes online only the primary goes down. Used for stateful applications where data about the client’s session is stored on the server
- Active-Active Two or more instances available simultaneously each instance can take some load for the application owing the entire system to take more load. Used for Stateless applications because if the application is stateful, there would be an issue if the customer's session isn't available on all instances.
EC2 Auto Scaling
- It is a service that allows you to add and remove EC2 instances based off of conditions that you define
- It is what allows us to provision more capacity on demand, depending on different thresholds we set on CloudWatch
- Example: Step Scaling Policy if you decide to add two more instances in case the CPU utilization is at 85%, and four more instances when it’s at 95%.
- Example: Target Tracking Scaling Policy creates the right alarms to track a target value of certain metric (verage CPU utilization, average network utilization, # requests)
- If there is an issue with an EC2 instance, EC2 Auto Scaling can automatically replace that instance ensure high availability.
- Main components to EC2 Auto Scaling:
- Launch template or configuration: What resource should be automatically scaled?
- EC2 Auto Scaling Group (ASG): Where should the resources be deployed?
- Scaling policies: When should the resources be added or removed?
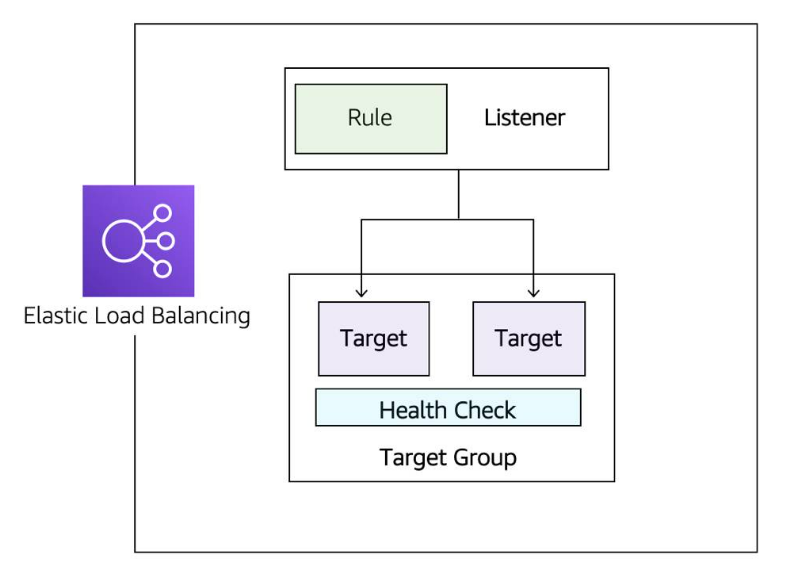
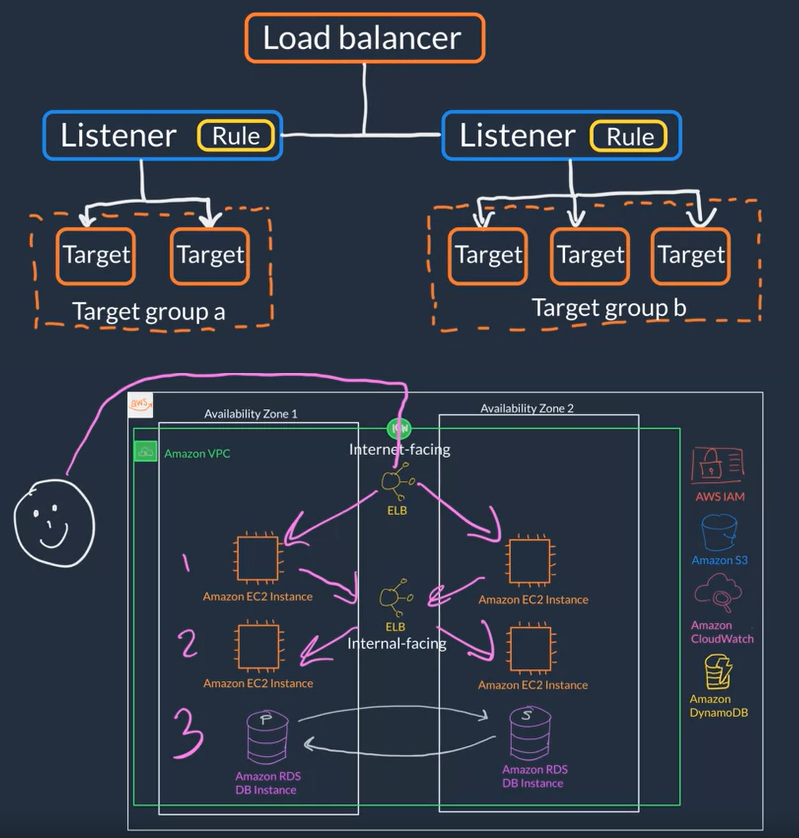
Amazon Elastic Load Balancer (ELB)
- It is a service that is highly available and automatically scalable. It can be configured to distribute requests across our servers/instances
- ELB Components
- Listener Component that listens for requests (client-side cause clients connect to it), specified with port and protocol, for example: port 80:HTTP, 443:HTTPS
- Targets/Target Group: The type of backend that will server the requests (server-side) for example: EC2 instance, lambda function, certain IP address
- Rules Defines how requests are routed to your targets (associates a target group to a listener) for example requests to certain route like www.your_website.com/info can be served by certain servers/intances if a rule defines this
- Health Check: It is check that is used by the load balancer to know a target group can start accepting traffic (Traffic is only sent to the a target group if it passes the health check.). For example a '/monitor' route on yout app that makes some basic calls to DB to get data or runs sure other basic test to make sure the services it needs are up then responds with '200 OK' if all basic tests passed. Types of health checks:
- Connection Check Establishing a connection to a backend EC2 instance using TCP, and marking the instance as available if that connection is successful.
- App Check Making an HTTP or HTTPS request to a webpage that you specify, and validating that an HTTP response code is returned.
- Types of load balancers
- Application Load Balancer (ALB) (Layer 7) Load balances HTTP and HTTPs traffic
- Network Load Balancer (NLB) (Layer 4) Load balances TCP, UDP and TLS traffic
- Gateway Load Balancer (GLB) (Layer 3+4) Load balances IP and third party applications traffic
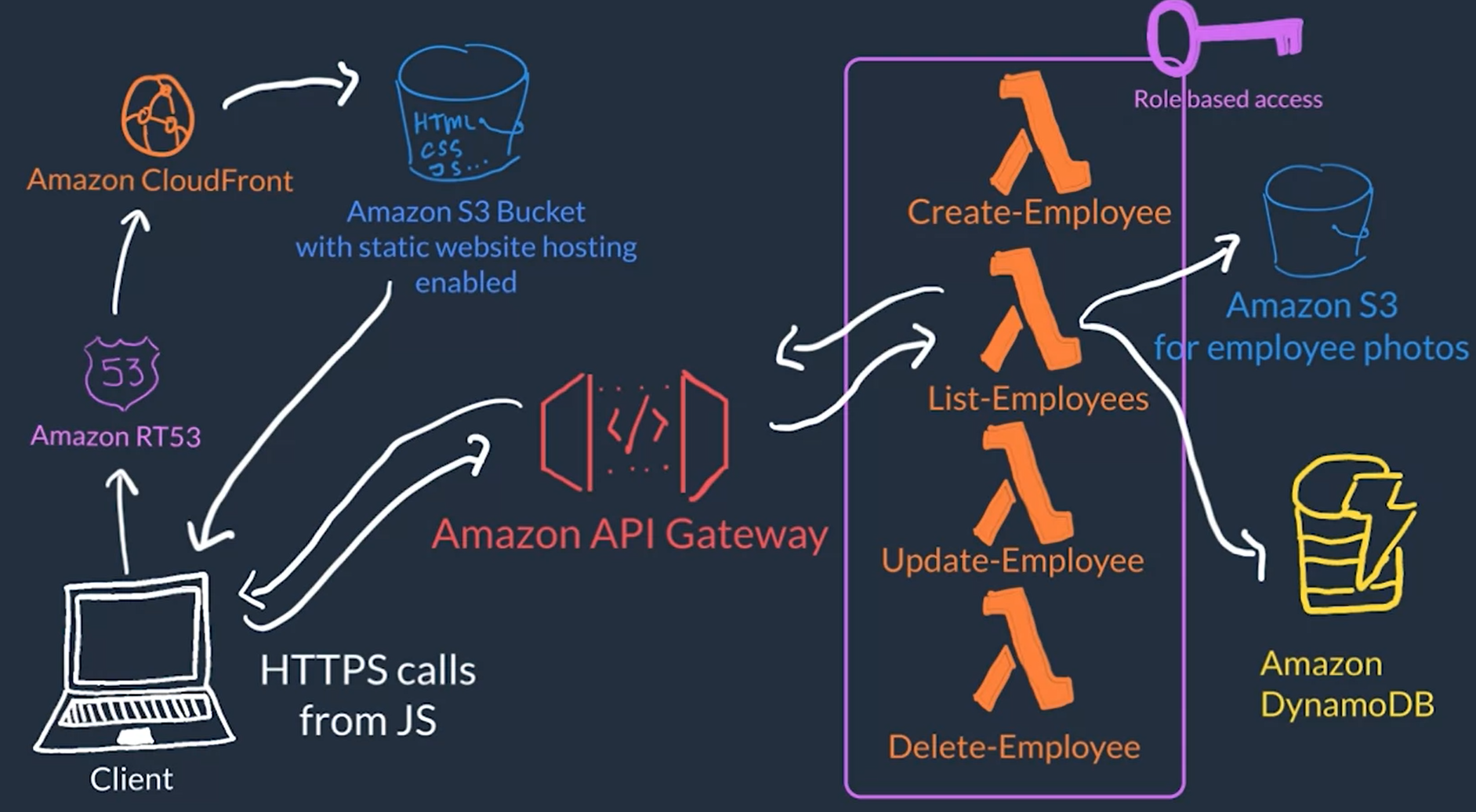
Serverless example on AWS
- Host you front-end or presentation layer on Amazon S3 as a stating website using JavaScript to make HTTP request
- Use Amazon API gateway to route HTTP request from the front-end to different lambda functions
- Have multiple Lambda Functions each provide different service
- Use IAM Roles so th lambda functions can access other services where data is store like Amazon S3 and Amazon DynamoDB
- Use Amazon Route 53 for domain name management for our website
- Use Amazon CloudFront cache the static assets, like the HTML, CSS, and JavaScript for better performance of our website
References