
Want to show support?
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
It is the science of encoding/encrypting and decoding/decrypting information
Symmetric key algorithms are the ones in which the key to encrypt is the same used to decrypt
Asymmetric Key algorithms are the ones in a pair of keys is used one to decrypt and one to decrypt
Caesar Cipher or Caesar Shift Take a letter and substitute that letter with another fixed number of positions down the alpaphet, the key is the value that determines the number of fixed positions used for the translation, if the end of the alphabet is reached we loop back to the start. It is a symmetric key algorithm
RSA Common used algorithm to encrypt data, is an asymmetric key algorithm, usually used to share key
Asymmetric algorithms cost more that Symmetric algorithms
Hash functions:
A secure cryptographic hash function has these extra properties:
Computationally efficient: It must compute the output in a reasonable amount of time
Collision free or Collision resistant:
x and y are such that, x != y then is hard to find H(x) == H(y)Hiding:
H(x) it's infeasible/very difficult to find the input x or anything related to the input.H(r | x)), which means the values are very spread out causing that it will be very difficult to find the inputPuzzle-friendly:
Sm in image below)sk)vk)sk if you only have the vksk the output is the signaturevk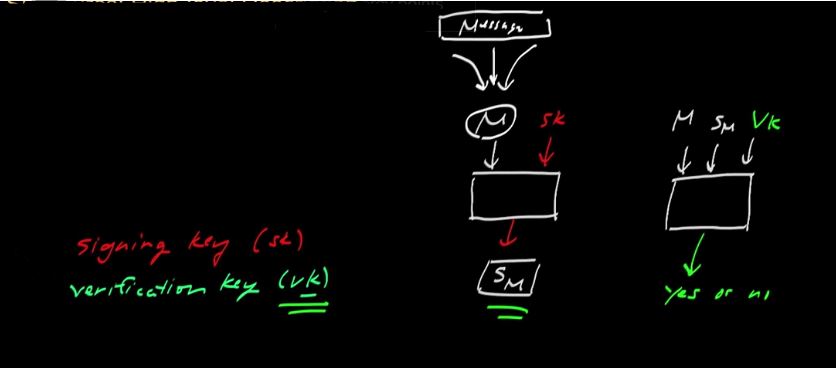
Hash pointer: it's a kind of data structure that has a pointer to some info and the hash of the info
tamper evidence: if somebody tries to alter data that is earlier in the log we can detect it
ASCII was invented to represent English letters, which was able to represent every character using a number between 32 and 127, since this was stored on a byte, top 128 characters were used for different people/orgs/industries for their own purposes
In the ANSI standard, everybody agreed on what to do below 128
For characters from 128 and on up there were different systems called code pages
Unicode was an effort to create a single character set that included every reasonable writing system on the plane
In Unicode, a letter maps to something called a code point which is still just a theoretical concept. How that code point is represented in memory or on disk is another story.
Encoding like UTF dictates how a character is stored in memory so for a particular character you need to know its encoding
almost every encoding in common use does the same thing with characters between 32 and 127,
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...