
Want to show support?
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
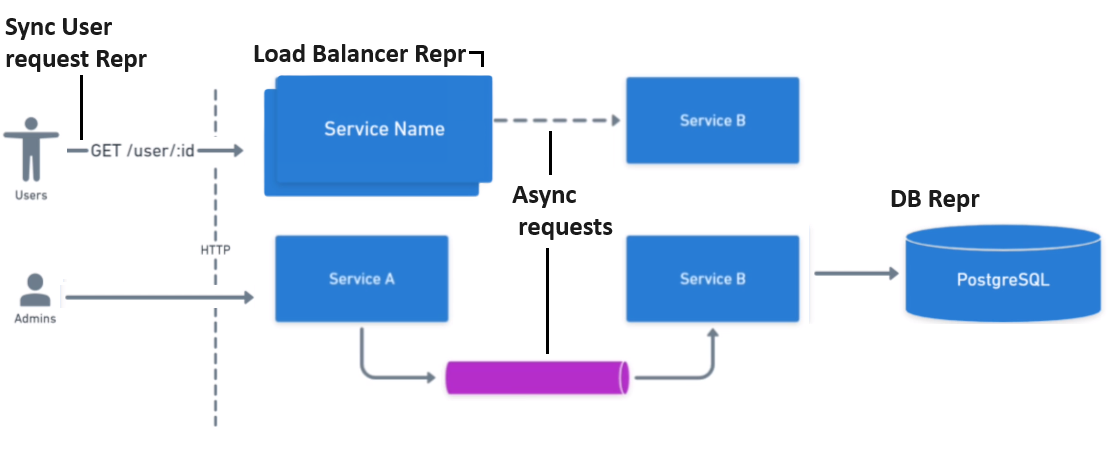
Stacked service boxes mean load balancer
Divider must have protocol use
DB are repesented as cylinders/barrels
Sync requests are represented with solid arrow and async requests are represented with queue cylinder or dotted line
Avoid crossing lines, follow left to right, top to bottom flow for diagram and align elements
The important thing to remember for System Design is: CPU Cache > RAM > Disk > Local Network > Global Network
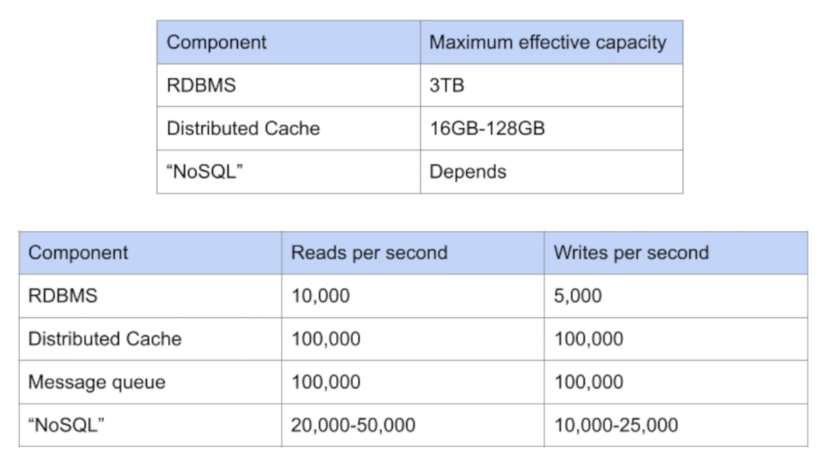
Capacity and throughput numbers to estimate if more than one instance of certain resource is needeed
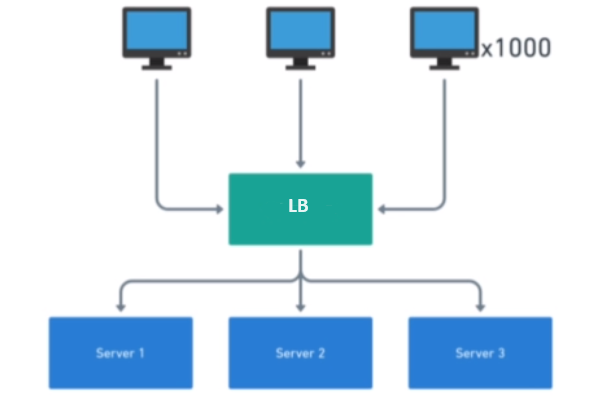
It may be a physical machine or a virtual machine, but it will be a separate instance from your app
Load balancer runs a software called a reverse proxy
The goal of this software is to distribute the traffic between multiple servers/services
Load balancer uses a stragegy to distribute traffic. For example:
Load balancer pros:
Layer 4
Layer 7
Push CDN
Pull CDN
+ we cache only what's needed- cache misses are expensive (slow) and require someone to implement this complexity+ We cache only what's needed, cache is abstracted from app, API deals with that complexity- Cache misses are expensive (slow) and API still deals with implementing complexity of dealing with a miss+ data needed from cache is almost always up-to-date- Writes are expensive and there is a chance that we will write data to cache that no one ever readd (redundant unused data)+ Write seems faster to user because slow storage is not accessed on every write - Not fullly reliable because if cache crash before the timeout occurs or before certain events happen we may lose data and not flushing data often enough may create inconsistencies.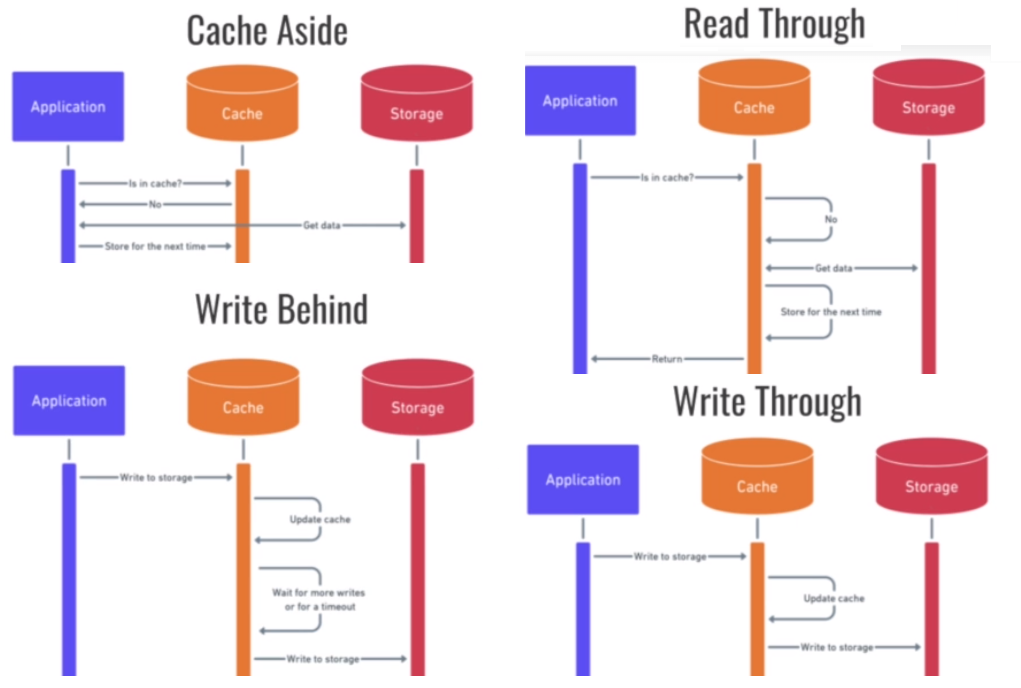
These are the strategies a cache can follow once it becomes to large
Eviction policies help us decide whci elements we should remove from cache
LRU (Least Recently Used):
LFU (Least Frequently Used)
GET /users/123GET /users/123/books/567PUT to switch state i.e. PUT /users/567/disable or PUT /users/567/enableGET to change entity or resource i.e. DONT: GET /users/123/enablePUT usually is idempotent (like a boolean if you set it twice to same value doesn't matter)POST usually is not idempotent (like a counter everytime you set it changes to different value)GET books?limit=10&offset=100The idea of invokin another service as if it were a local function
Process
Add a level of abstracion to instead of using a specific language use and IDL
gRPC: It is an RPC protocol that uses Protobuf as IDL and HTTP2 as transport, not supported by browsers
.proto files, it is not human readable and smaller/faster than JSON or XML| Protocol/Usage | External API | Bi-directional | High Thoughput | Web browser support |
|---|---|---|---|---|
| REST | Yes | No | No | Yes |
| WebSockets | Yes | Yes | Yes | Yes |
| gRPC | No | No | Yes | No |
| GraphQL | Yes | No | No | Yes |
| UDP | Yes | Yes | Yes | No |
kill -9 PSN), Pipes (stdout, stdin, etc.), Sockets (establish a connection)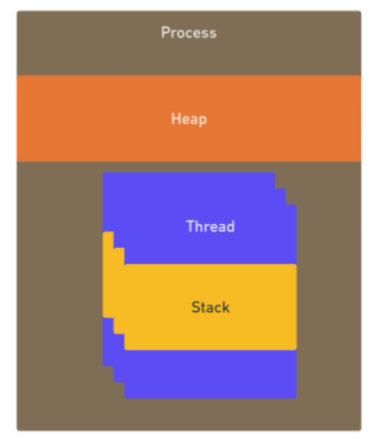
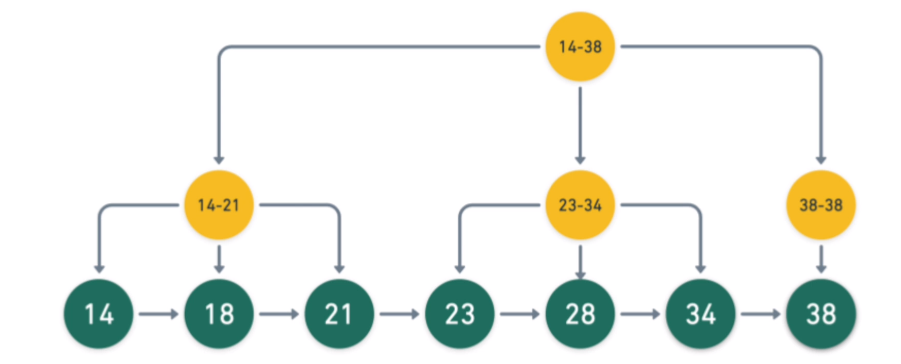
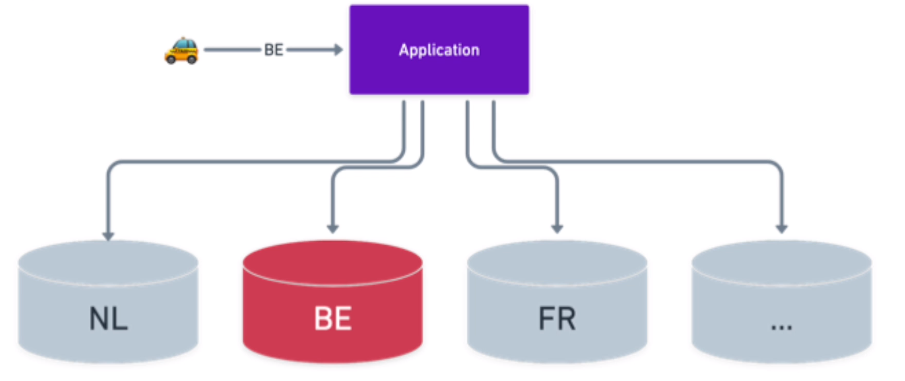
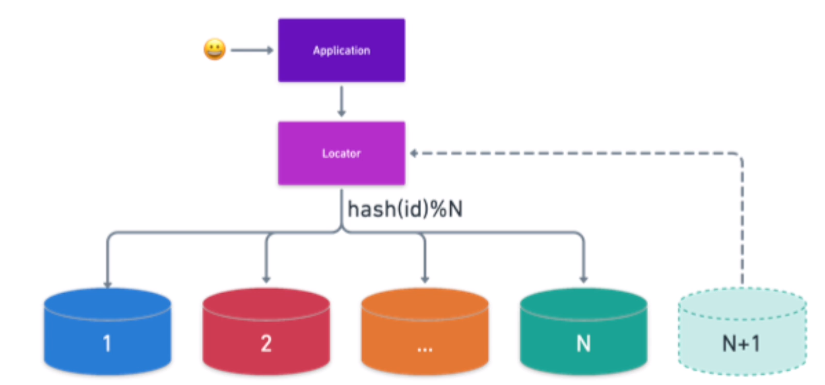
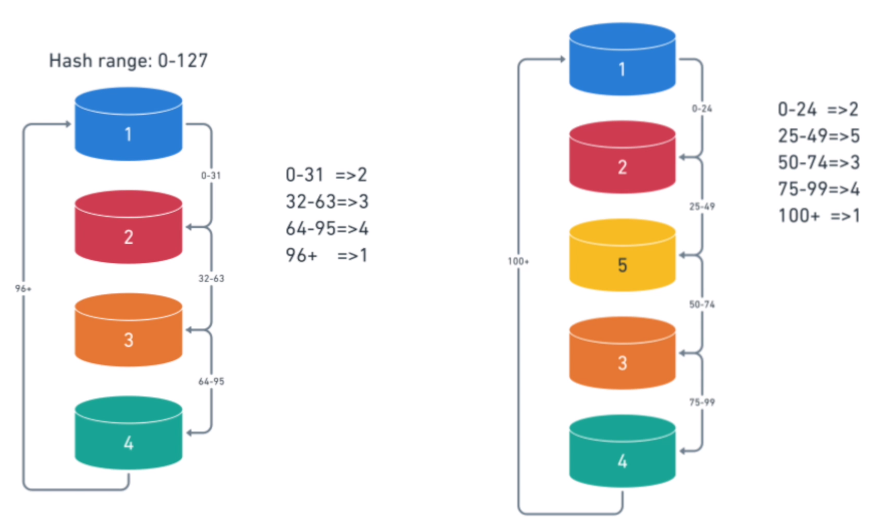
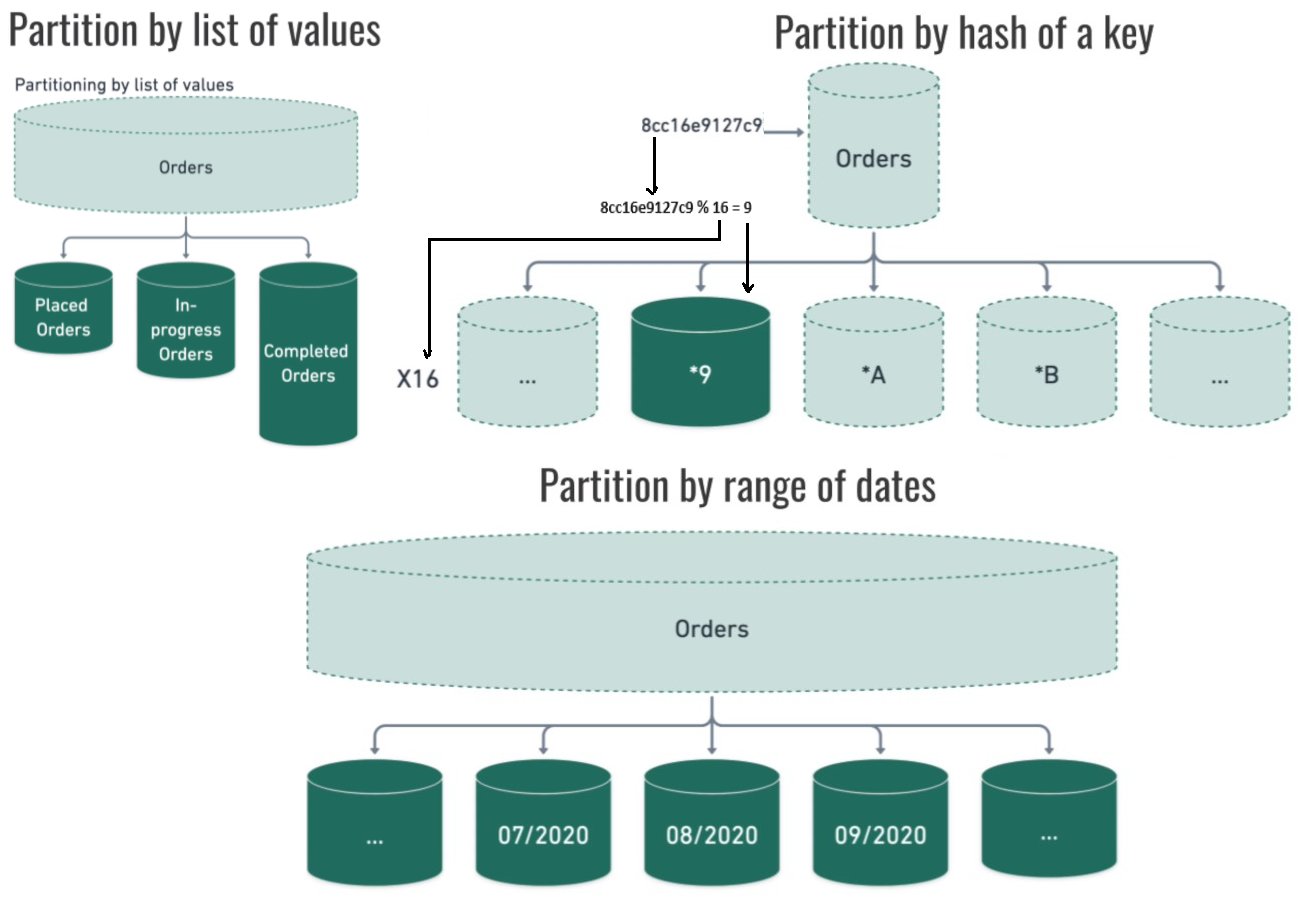
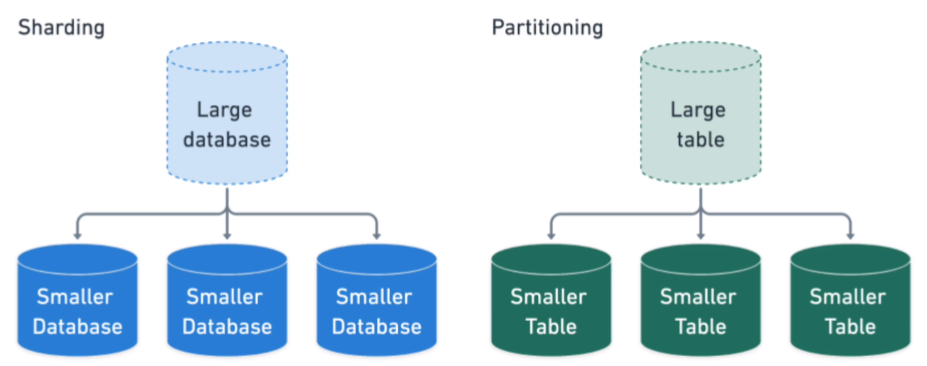
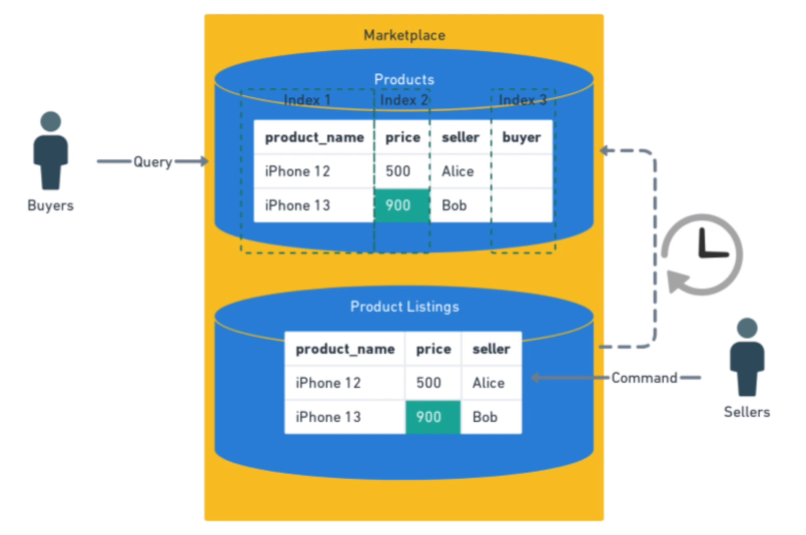
Sharding is breaking one large database into smaller databases. Partitioning is breaking one large table into smaller tables.
Atomic
Consistency
Isolation
Durability
Having an ACID implementation is complex and anything complex is usually slow
It is the concept used to preserve state between HTTP requests
Cookies are a client side solution to support state on HTTP
Sticky sessions:
Key-Value store:
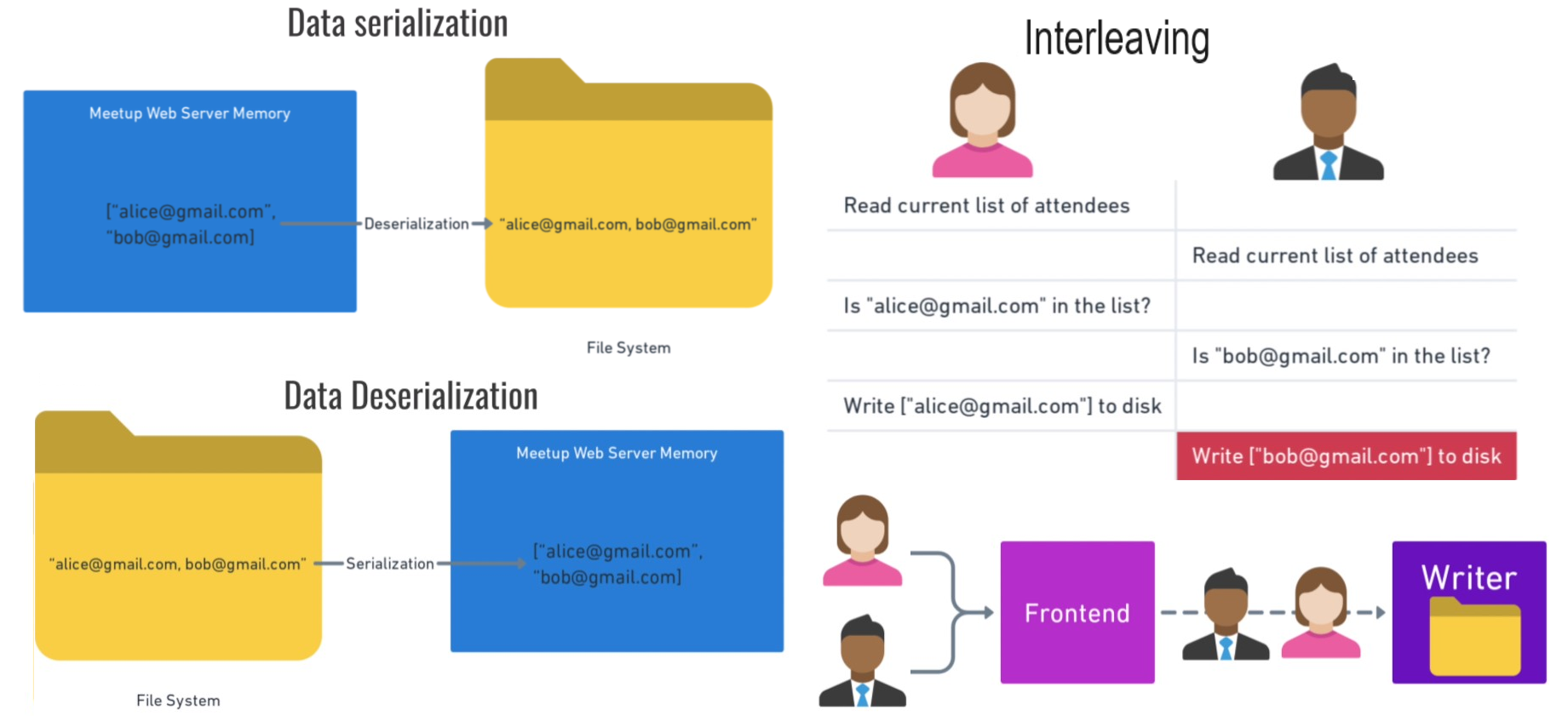
Data serialization is converting between raw bits & bytes to data structs while Request Serialization means processing requests from start to finish sequentially
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...