
Want to show support?
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...
My personal notes from Uncle Bob clean code lectures and video episodes, they have been paraphrased or written in my own words just for my personal reference, in some cases adding my personal opinions about certain topics
We make a mess because we want to go fast but the only way to go fast is to go well
Adding people doesn’t make things go fast because it is the old code that is actually training the new people so the code slows programmers
No one writes clean code at first attempt, once the code works it most likely be a mess, after that it is when you need to clean it
Having code that works is only half the job. It will take you half of your time to make it work, clean it will take the other half
You are not done when it works, you are done when it is right
Clean code does one thing well
You must write code that other people can maintain, making it work is not enough
It is more important that your peers understand the code your write than the computer understand the code you wrote
Unclean code characteristics:
Clean code allows the reader to exit early when reading it
Use intention-reveling names, choose a name that reveal the intention of the thing you are trying to name. In other words stuff should describe itself for example it is better to have variable that describe itself than a variable followed by a comment with a description
Choose names that communicate your intentions in the code and are pronounceable
Encodings like Hungarian Notation are a thing of the past, they just obfuscate the code
Declare explanatory variables, the purpose is to explain what its content is
Boolean variables or functions/methods that return a Boolean should be written like predicates (is_empty, is_pending, is_active, etc)
Try to do
elapsedTimeInDays = 100 window_size_in_months = 7 number_of_pass_scenarios = 0 is_terminated = True name = "John"
Avoid
d = 100 # Elapsed time in days wsim = 7 qty_pass_s = 0 terminate = True s_name = "John"
Function names should be verbs because they do things, while Classes, variables or attributes should be nouns/noun-phrases and Enums usually are adjectives because they tend to be names or object descriptors
Name of a variable should be proportional to the size of the scope that contains it, long scopes need long names. This is the reason i, j or d are good a variable names if for example they are used on a short loop. Variable names should be short if they are in small scope and long if they are in big scope
Name of functions and classes should be inversely proportional to the size of the scope that contains it:
open(), close(), serve(), etc.)Try to do
from enum import Enum
class TransactionStatus(Enum):
PENDING = auto()
CLOSED = auto()
CANCELLED = auto()
if transaction.is_cancelled():
cancel_reason = transaction.get_cancellation_reason()
...
Avoid
# TODO
A function should be small, do one thing, do it well and do it only.
Function-call overhead is in most scenarios a thing of the past we should take advantage of the power of our current hardware to partition our software for readability first
A set of functions that manipulate a common set of variables is a class
Two or three arguments per function, if you already have 5-6 things to pass into a function, if they are so cohesive (related to each other) to be passed into a function together maybe they should be a class
Try to avoid passing Booleans to functions create separate functions, when you pass a Boolean you are saying that your function has two paths or does two things, one for the True case and another for the False case
No output arguments if possible in functions use ONLY the return value to pass data out of a function
Avoid functions that can take None or null or expects one of these invalid values because we are saying the function handles two possible states, one for the null case and one for the non-null case, write to functions one that takes no arguments (for null case) and one that takes one single argument (for non-null case)
Try to avoid defensing programming, checking for null/None checks and error code checks, try to write code that prevents you from passing null/None values
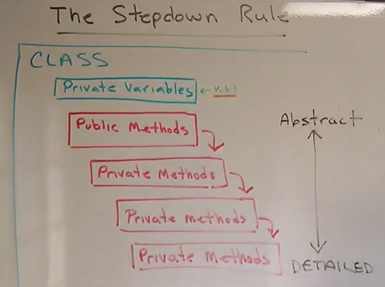
The Stepdown Rule: Important stuff at the top and the more specific or detail oriented stuff at the bottom, avoiding backward references. Every functions calls children function which then call their own children's function, we order functions in the order they are called and in the order of their hierarchy
try block small or better yet make it just be a function callIf a module A calls a function from module B directly we have two types of dependencies:
B loaded and ready in memory when we execute module AA has some type of include/import of module BIf we use an Object Oriented (OO) paradigm we can manage the source code dependency by making A dependent of an interface and module B derives from the interface, this allows modules to be deployed separately. Module B is a plugin to A
.jar files and DLLs are dynamic linking objects which means everything's is loaded and linked at runtime, they exists so you can independently deploy chunks/modules of your system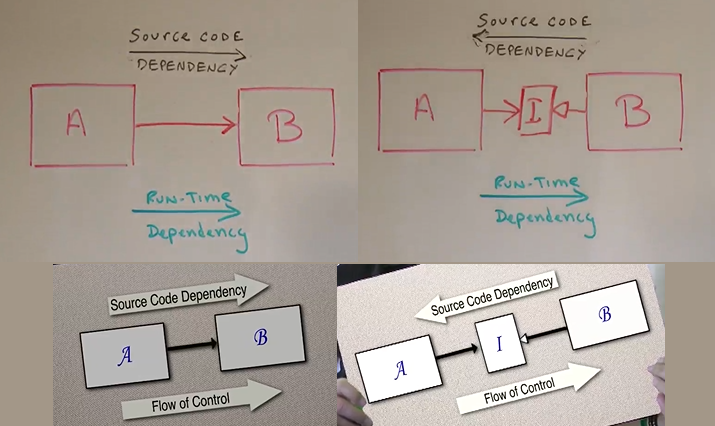
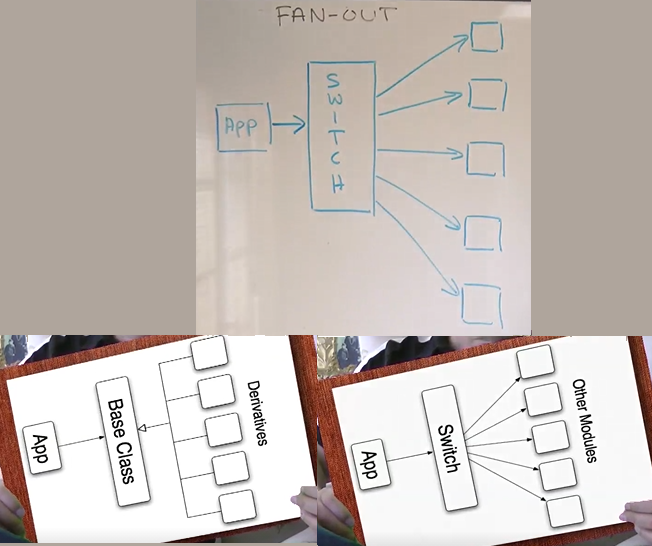
To avoid switch/if-elif-else dependencies problems we can use Polymorphism or move the statement to a sections of the code that we know won't grow
Dependency Inversion: We should be able to draw a line that separates the core app functionality (App partition) from the low-level details(Main partition)
Runtime and source code dependencies should point towards the direction of the application
There should be only a few entry points from main into the application, let main do rest of the work with factories implementations and strategies patterns (abstract interfaces or skeletons will be in the app side) and nothing that happens in the application should affect the main partition
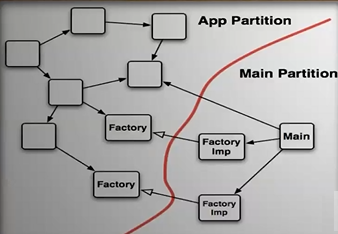
switch statements that live in the main partition usually are OK as long as all the cases stay in the main partition as well
The system should be composed of independently deployable plugins (main partition), all of those plugins should know about the central core of the application partition but the application partition shouldn't know anything about the plugins at all
Sequence, selection (branching) and iteration are the invariants (stuff that never change) in software, they are the fundamental blocks of software
The main SW development paradigms are 3: Structured, Functional and Object-oriented
Functional programming is the paradigm where we cannot change the state of variables, this means no assignment statements so therefore no side effects
Side effect refers to code (or function) that changes the state of the system:
open or new have side effects because they leave a file opened or leave a block of memory allocated, before calling the function the system had a state that was using certain amount of memory after calling the function it has a state in which it uses more memoryWhen functions must be called in a order we have temporal coupling or when we depend on one thing happening before or after another E.x. when you use a database you are coupled to the fact that you have opened a DB connection then do some stuff and finally close the connection
class FileCommand():
def process(to_process_file):
print("Processing of {} happens here".format(to_process_file))
def open_file(my_file, my_file_command):
my_file.open()
my_file_command.process(my_file)
my_file.close()
open_file(open("my_file.txt", "w"), FileCommand())
Command and query separation: Functions that change state should return nothing while functions that return values should not change state
Avoid functions that change state (Commands) AND return values, this violates command query separation
Try to do
class Auth():
def login(username, pass):
# Call code that returns if login was possible here
login_successful = True
if not login_successful:
raise Exception
authorize = Auth()
authorize.login(username, password)
user = authorize.get_user(username)
Avoid
class Auth():
def login(username, pass):
# Call code that returns if login was possible here
login_successful = True
if login_successful:
return User(username)
else:
return None
authorize = Auth()
user = authorize.login(username, password)
Tell Don't Ask: You should tell objects to do the work not asking what their state is or whether they could perform the work
Law of Demeter:
Try to do
my_object.doSomething()
Avoid
my_object.getX().getY().getZ().doSomething()
null/None is not an error is a value when tempted to return those check if using exceptions is bettertry blocks are in function it should be the first thing before any declarations and should have very few lines or better yet a single function call
# python -m unittest py_stack.py
from unittest import TestCase
from abc import ABC
class Stack(ABC):
def get_size(self):
pass
def is_empty(self):
pass
def push(self, element):
pass
def pop(self):
pass
def top(self):
pass
def find(self, to_search_element):
pass
class Overflow(RuntimeError):
pass
class Underflow(RuntimeError):
pass
class IllegalCapacity(RuntimeError):
pass
class Empty(RuntimeError):
pass
class BoundedStack(Stack):
class ZeroCapacityStack(Stack):
def get_size(self):
return 0
def is_empty(self):
return True
def push(self, element):
raise Stack.Overflow()
def pop(self):
raise Stack.Underflow()
def top(self):
raise Stack.Empty()
def find(self, to_search_element):
return None
def __init__(self, capacity):
self.capacity = capacity
self.size = 0
self.elements = []
@staticmethod
def make(capacity):
if capacity < 0:
raise BoundedStack.IllegalCapacity()
elif capacity == 0:
return BoundedStack.ZeroCapacityStack()
return BoundedStack(capacity=capacity)
def get_size(self):
return self.size
def is_empty(self):
return (self.size == 0)
def push(self, element):
if self.size >= self.capacity:
raise BoundedStack.Overflow()
self.elements.append(element)
self.size += 1
def pop(self):
if self.is_empty():
raise BoundedStack.Underflow()
element = self.elements.pop(self.size-1)
self.size -= 1
return element
def top(self):
if self.is_empty():
raise BoundedStack.Empty()
return self.elements[self.size-1]
def find(self, to_search_element):
for i, e in enumerate(self.elements):
if to_search_element == e:
return i
return None
class StackTest(TestCase):
def setUp(self):
self.my_stack = BoundedStack.make(2)
def test_just_create_stack_is_empty(self):
self.assertIsNotNone(self.my_stack)
self.assertTrue(self.my_stack.is_empty())
self.assertEqual(0, self.my_stack.get_size())
def test_after_one_push_stack_size_must_be_one(self):
self.my_stack.push(1)
self.assertEqual(1, self.my_stack.get_size())
self.assertFalse(self.my_stack.is_empty())
def test_after_one_push_and_one_pop_stack_size_must_be_empty(self):
self.my_stack.push(1)
self.my_stack.pop()
self.assertTrue(self.my_stack.is_empty())
def test_when_pushed_past_limit_stack_overflows(self):
self.my_stack.push(1)
self.my_stack.push(1)
# self.assertRaises(BoundedStack.Overflow, self.my_stack.push, 1) # Also valid
with self.assertRaises(BoundedStack.Overflow):
self.my_stack.push(1)
def test_when_pop_past_zero_stack_underflows(self):
# self.assertRaises(BoundedStack.Underflow, self.my_stack.pop) # Also valid
with self.assertRaises(BoundedStack.Underflow):
self.my_stack.pop()
def test_when_one_is_pushed_one_is_popped(self):
self.my_stack.push(1)
self.assertEqual(1, self.my_stack.pop())
def test_when_one_and_two_are_pushed_two_and_one_are_popped(self):
self.my_stack.push(1)
self.my_stack.push(2)
self.assertEqual(2, self.my_stack.pop())
self.assertEqual(1, self.my_stack.pop())
def test_when_creating_stack_with_neg_size_must_raise_IllegalCapacity(self):
with self.assertRaises(BoundedStack.IllegalCapacity):
BoundedStack.make(-1)
def test_when_creating_stack_with_zero_size_any_push_should_overflow(self):
with self.assertRaises(BoundedStack.Overflow):
local_stack = BoundedStack.make(0)
local_stack.push(1)
def test_when_one_is_pushed_one_is_on_top(self):
self.my_stack.push(1)
self.assertEqual(1, self.my_stack.top())
def test_stack_is_empty_top_raises_empty(self):
with self.assertRaises(BoundedStack.Empty):
self.my_stack.top()
def test_with_zero_capacity_stack_top_raises_empty(self):
with self.assertRaises(BoundedStack.Empty):
local_stack = BoundedStack.make(0)
local_stack.top()
def test_given_stack_with_one_two_pushed_find_one(self):
self.my_stack.push(1)
self.my_stack.push(2)
self.assertEqual(0, self.my_stack.find(1))
self.assertEqual(1, self.my_stack.find(2))
def test_given_stack_with_no_two_find_two_must_return_None(self):
self.my_stack.push(1)
self.my_stack.push(3)
self.assertIsNone(self.my_stack.find(2))
Open close principle: a module should be open for extension but closed for modification, you should be able to extend the behavior of a module without modifying that module, this is usually implemented with base classes and derivatives
Science is a set of theories, conjectures, hypothesis that cannot be proven correct, experiments can prove them false but never true, we have not proven that airplanes can fly, we have just surround with so many tests, it doesn't matter we don’t prove it correct, we can do the same with software by surrounding with tests, we demonstrate our software is not incorrect
Why would we write code but don't write tests for every line of code? why don't we test the individual lines we write?
Any fool can write code that a computer can understand but it takes a good programmer to write code a human can understand :: Martin Fowler
Purpose of a comment is to explain the code that cannot be explained by the code itself
Comments are to compensate for our failure to express ourselves in code, so every comment represents a failure and you will certainly fail, that's OK but consider the comment as a unfortunate necessity
Don't comment first, try everything else first, use a comment as last resort
Comments are a lot of times bad because we don't maintain them
Comments don't make up for bad code, try to clean the code if you fail, that's fine write a comment and move on but REALLY try to clean the code first
Explain yourself with code not with comments, make the code express itself
Never comment about code that is somewhere else
Reserve comments for local stuff, if we write comments that are not local when some other part of the code is changed it may invalidate our comment
Use comments to document public APIs and generic functions/methods that other programmers will use
Try to have if statements and while loops of only one line
Big projects do NOT imply big files (Smaller is better)
Use blank lines to separate topics or processes in code. Things that are related to each other should be closed to each other
Length of lines of code should be of any length as long as you don't have to scroll right to see (max 100 or 120 characters)
Classes are containers of methods/functions that hide the implementation of the data they manipulate
Minimize getters and setters in class and try to maximize cohesion
Don't just expose variables through simple getters, abstract information you want to expose
Methods operate on data but tell you nothing about how that data is implemented, when they expose data they exposed in the most abstract way
Try to do
class Car():
def __init__(self):
self.fuel = 0
def get_fuel_percent():
pass
class ElectricCar(Car):
def calc_fuel_electric_car(self):
# You would implement the particularity of
# getting fuel percent for electric car here
return self.fuel*2 + 1
def get_fuel_percent():
return self.calc_fuel_electric_car()
class NuclearCar(Car):
def calc_fuel_nuclear_car(self):
# You would implement the particularity
# of getting fuel percent for Nuclear car here
return self.fuel*3.1416 + 1000
def get_fuel_percent():
return self.calc_fuel_electric_car()
Avoid
class Car():
def __init__(self):
self.gallons_of_gas = 0
def get_gallons_of_gas():
pass
"""
You need to forget get_gallons_of_gas because
it doesn't make sense for other types of cars, so
you end up with a useless class hierarchy
"""
class ElectricCar(Car):
def __init__(self):
self.battery_level = 0
def get_battery_percent():
return self.battery_level
class NuclearCar(Car):
def __init__(self):
self.energy_level = 0
def get_nuclear_energy_level():
return self.energy_level
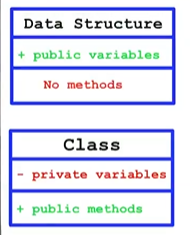
Data Structures are containers of data with no cohesive methods
A data structure is very different from a class because it has a bunch of public variables and virtually no methods while classes should have a bunch of public methods and try to have no public variables
Data structures can have methods but they should only manipulate individual variables they don't manipulate cohesive groups of variables like methods of a class do
Methods of a data structure expose implementation they don't hide it nor abstract it like classes
You can't tell a data structure to do anything you can only ask it questions
We use classes and objects when it's types that are more likely to be added we use switch statements and data structures when it's methods that are more likely to be added
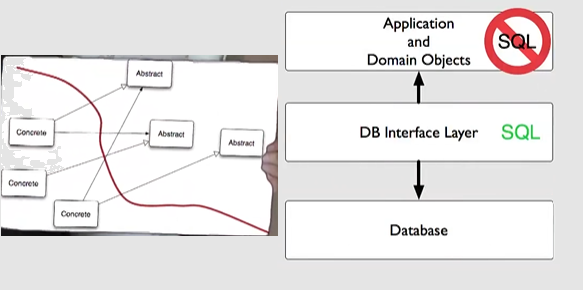
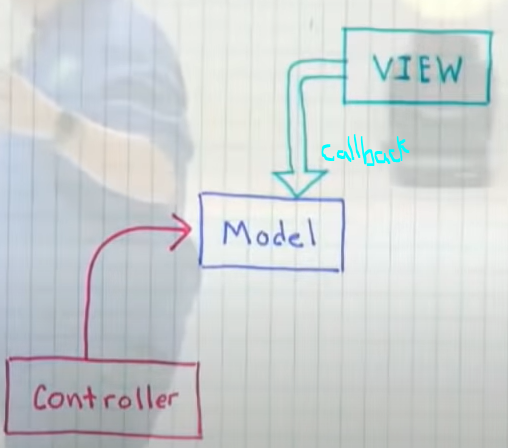
Boundaries separate things that are concrete from things that are abstract in our system:
For each boundary one side is concrete implementation the other side is abstract definitions. E.x. Main, DB & View are concrete while App, Models, Domain are abstract,
All the source code dependencies point from concrete to abstract (imports are in concrete side). E.x. Main, DB & View depend on the App, Models & Domain
Impedance Mismatch: When we define classes in the application side with methods these usually don't look like database tables or database schema
It is the responsibility of the interface between the DB and the APP to convert the data structures that live in the database to business objects that app uses and the layer needs to do this without letting the app know it exists
Views should know about the app, the app should know nothing about the views
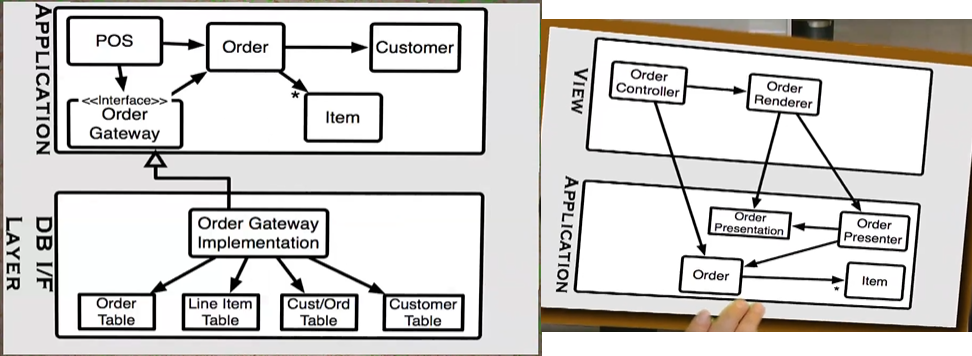
Often the more concrete side will be composed of data structures that use switch statements
The way we imprint professionalism into the SW development profession is by setting high expectations like:
This means don't be afraid of the code, don't be afraid to clean it, to improve it and restructure it
Avoid the "if ain't broke don't fix" mentality
If we choose change the code in a way to minimize the risk of breaking it instead of changing it to improve the general structure then the code will just rot and get worse with time, the productivity will slow to a point it is not possible to make a change without breaking something
To be fearless you need confidence to have confidence you need feedback mechanisms that run fast, are easy to run and tell you everything is OK, in other words tests
Fragile test problem: When test are so coupled to the system that if you change something in the system the whole test suite break
To avoid the fragile test problem we need to consider tests are part of the system so need to be designed as part of it with the same techniques to have a good design. They need to be decoupled from the system
The definition of bad design is a design that when you make a change in one part that change breaks a lot of things in another part
Architecture includes the grand shape of the system and the teeniest low level design, includes the most abstract of the module interfaces and the most concrete of the method implementations
The Architecture is the shape the system takes in order to meet its use case
Architecture is not about the tools we use like (IDE, GUIs, language, dependencies, frameworks, databases, etc.) it is about usage and communicates intent, architecture tells you how a system it is being used, it's about the use cases
A good architecture is a SW structure that allows you to defer critical decisions about tools and frameworks (GUIs, webservers, DBs etc) for as long as possible, defer them to the point where you've got enough information to actually make them or not make them at all, allows you to defer majors decisions until the last responsible moment. A good architecture decouples you from tools, frameworks & databases
Architecture needs to be focused on use cases not on software environment
Make the GUI and database a plugin into the business rules
Using a framework comes with a great commitment to the framework
Architecture must be flexible because as we implement it, the code and modules starts imposing pressure on the architecture which changes the shape of the architecture and this change continues every time a new feature is added
The architecture is a living thing, it changes with the system on a day to day basis
Good architecture results in good structured SW in which the effort to build it, to maintain it and the struggle to continue to add new stuff to it is minimized while the functionality and flexibility is maximized
The goal of SW architecture is to minimize the effort and resources required to build and maintain a software system
Quality of design can be measured by measuring the amount of effort it takes to meet the needs of a customer, if effort increases design quality decreases (it is bad) while if effort remains constant of shrink with time then design is good
We want to go fast and become overconfident we will be able to deal with the mess later, so the mess builds slowly but inevitably and eventually it is so big it dominates everything about the project
We need to build in a steady, consistent, clean way so that so that we can continue to go as fast as possible, which may not be very fast but at least it is not going to slow down
The key to go fast is to not slow down
A discipline may feel slow even if it is actually speeding you up. A good discipline may feel slow but will speed you up
SW has two values the value of what it does and the value of its structure but we tend to focus on what the SW has to do (satisfy the requirements) and if we do that we are maximizing the fact that it works today at the expense of making it flexible and being able to change so when the requirements change (and they will, they always change) the cost to change it will be enormous and if the cost is to big that will just kill the project
Programmers know we need to build a structures that supports the requirements, while stakeholders only know/see the requirements, programmers need to communicate the importance of structure
We (Programmers) tend to be bad at emotional conformation and relating emotionally to people
Behavior is urgent structure/architecture is important, because it has an extreme long term value while the requirements are urgent because they have a short term value
Focus on important and urgent, also on the important but not urgent
Architecture should express the intent of the application
The web, databases, frameworks and other system components are just I/O devices from the SW developers point of view
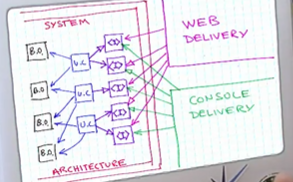
Description of how the user interacts with the system in order to achieve a specific goal
We need to abstract the uses cases from UI or web based interactions like (buttons, screens, pop-ups, droboxes, checkboxes, input fields, etc)
Use cases need to be independent of the delivery mechanisms (the web, a console, a GUI, etc)
Use case must be an algorithm for the interpretation of input data and generation of output data
We need to make the uses cases as agnostic as possible about delivery mechanisms, frameworks, databases, corporate standards, etc
A use case talks about the data and the commands that go into the system and the way the system response

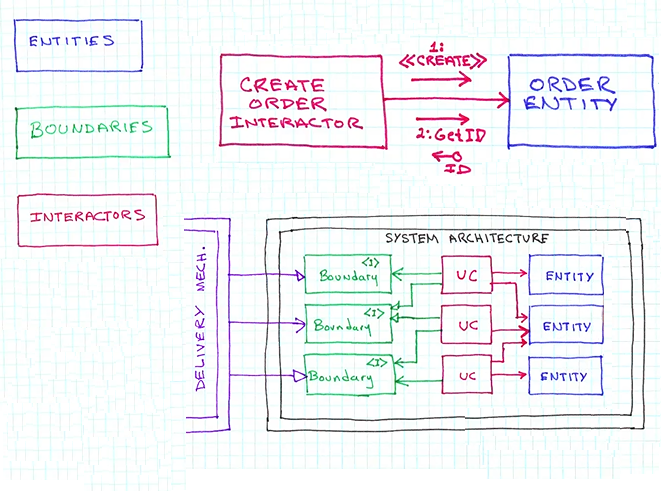
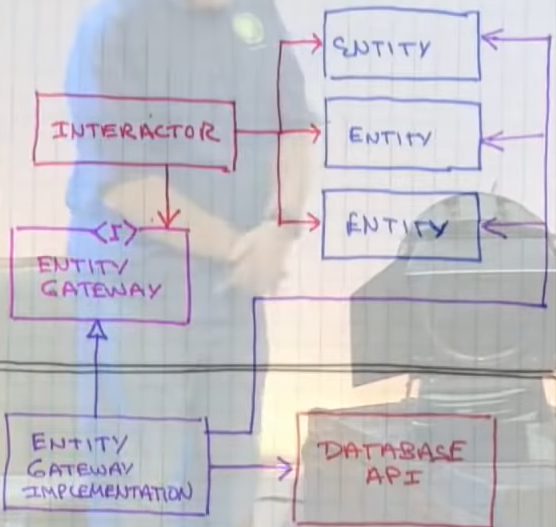
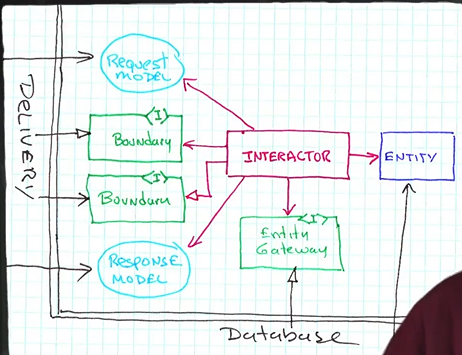
Object Oriented Use case driven: Interactor/Control Object (object that represents a use case, which is a application specific business rule) guides/coordinates the execution of the entities, which represent the actual business rules controlled by the interactor, then there is data in and out of the system, the data movement of data is done through interfaces or boundary objects, interactor uses the input boundary objects to push data across the entities and the methods on the boundaries allow data to go in and out of the system
Object Oriented Use case general process:
Request and result models are just plain data structures or objects
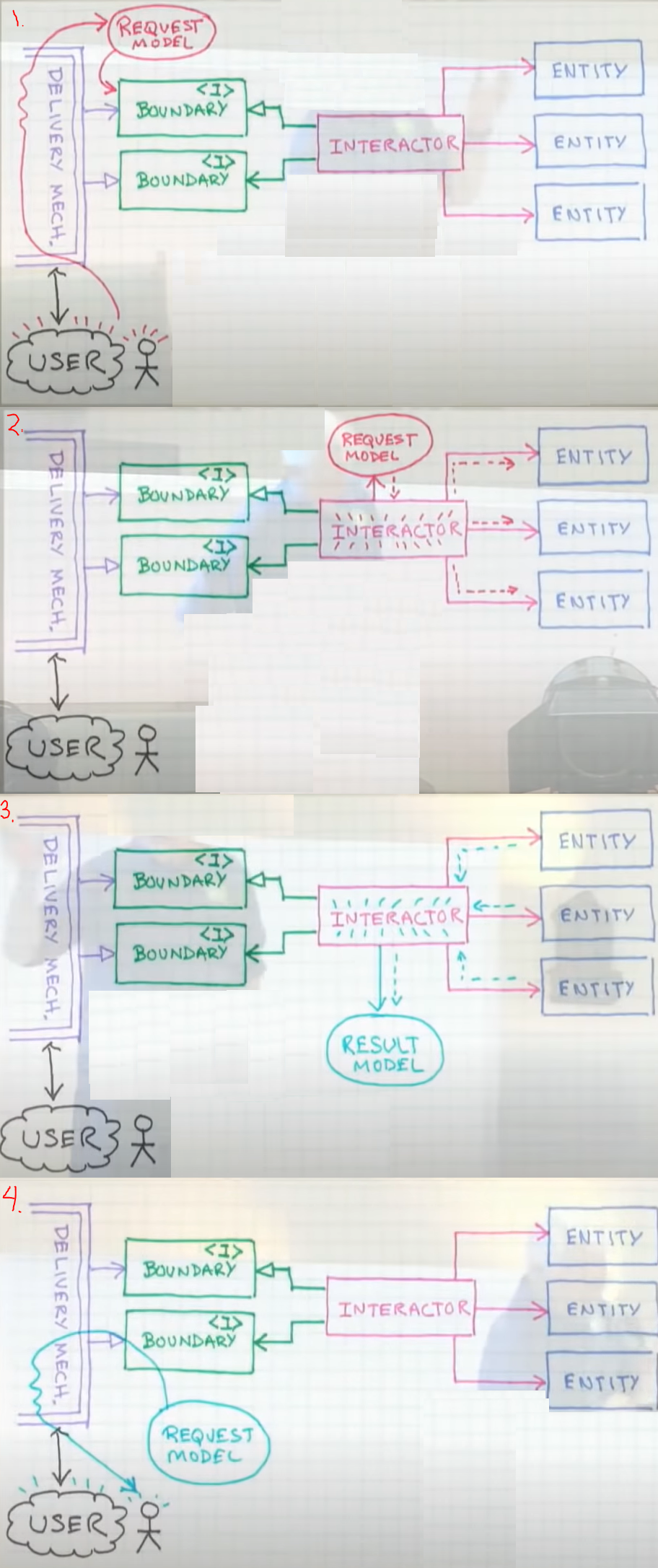
Interactors and entities should know nothing about the delivery mechanisms, they should be plain old objects operating on data
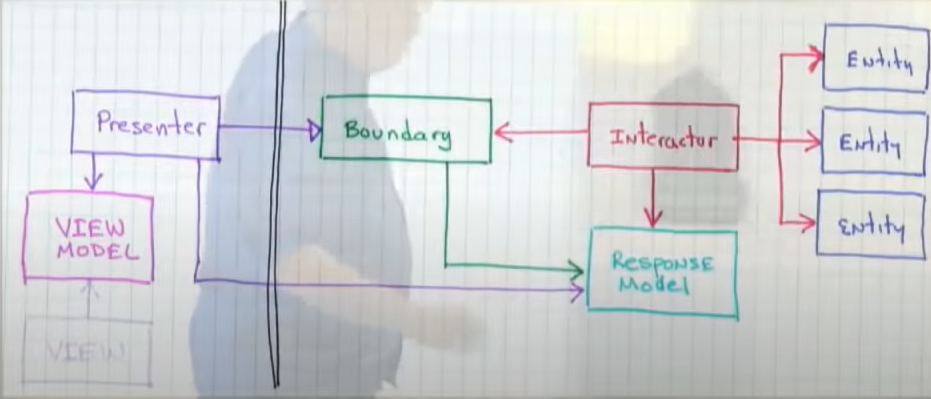
Interactors take in request models, produce response models, pass the data through the boundaries, controllers are the ones that pass data into the interactors while the presenters are the ones that take data and present it to the view
Boundaries are a set of interfaces:
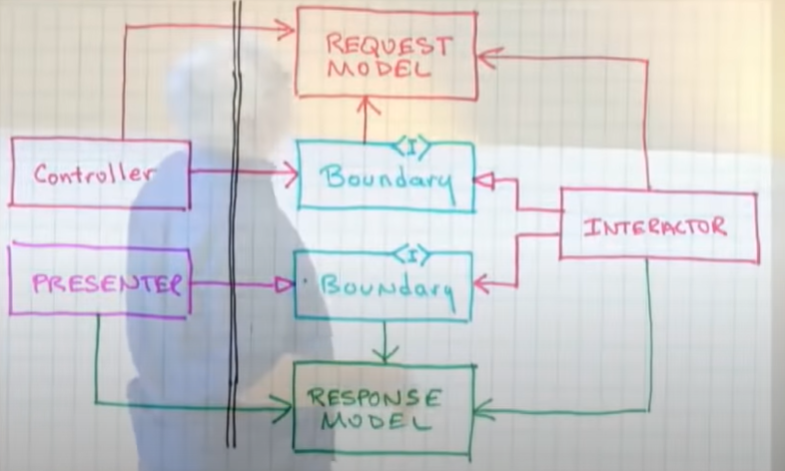
We don't want the things that perform business rules/operations coupled to database language like SQL, we need and entity gateway that has an interface (not implemented methods) for every query we want to perform, then we have the entity gateway implementation that has the knowledge on how a specific database works, if we have an SQL database all the SQL will be in the implementation
Interactor objects uses the database abstraction (entity gateway interface methods) on the application side, the implementation of those abstractions
The reason we manage is because mismanagement cost a lot (meaning, produce the wrong product, create a product of inferior quality, work 80 hours a week, etc)
Good (quality), Fast (Time to Market), Cheap (Cost effectiveness), Done... Pick only 3 the fourth you will not get it.
Agile is a way to produce data to destroy hope, to know how messed up things really are
Dates are fixed because the obey business, for example it has to be done by November because we ran out of money in December
Requirements change all the time because they users/customers don't know what they want, the more we talk about what they want they kind of get a better idea of what they want but they really don't know until they see something execute that is not what they want so then they say "oh yeah that is not what I wanted"
We need to get things in front of customers very early so they can tells us "oh that's not what I wanted, I know that is what I said but now that I see it I realize it is not what I want at all", we need to start this feedback cycle fast
Waterfall model in which we analyze, then develop then implement doesn't work because once you start implementing you realize requirements were not clear and design won't really help solve the problems we want so the only solution is to do everything at the same time
On Agile we do exploration phase that involves doing analysis,design and implementation the first 3-4 sprints to be able to estimate how much we can get done in average in a sprint and extrapolate when we will actually be done, we will realize we wont be able to do everything by the end of date so we make adjustments
Doubling staff does not double throughput because old people slow down due to they need to help ramp up new people and expecting new people to get faster by an arbitrary date (in a month for example) is risky because you really don't know that, you don't have data to know that and even if you have data it is not reliable because varies from person to person
We must focus on never ever deliver something you stakeholder don't need
The problem with estimates is that we need to tell a moron (computer) how to do something
Agile is not to go fast is to get the bad news as early as possible
Scrum is a business facing process, then there are the engineering practices and the team behaviors
The purpose of an iteration is to produce data and measure how much can get done, an iteration doesn't fail because even if no points are done that is actually a result with data
Write acceptance test that defines done for every story so a programmer knows he is done when an acceptance test for that story pass, so acceptance test must be done by midpoint of the sprint
Seniors developers should spend most of their time pairing with other people, mid level people should spend some time pairing with junior people
If we have story that we don't know how long it should take, we can define a spike, which is a story to try to figure out how long it should take you to finish the first story
You need to try as best and as hard as you can to follow clean code practices and rules but sometimes the rules cannot hold all the time so we violate the rules
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...