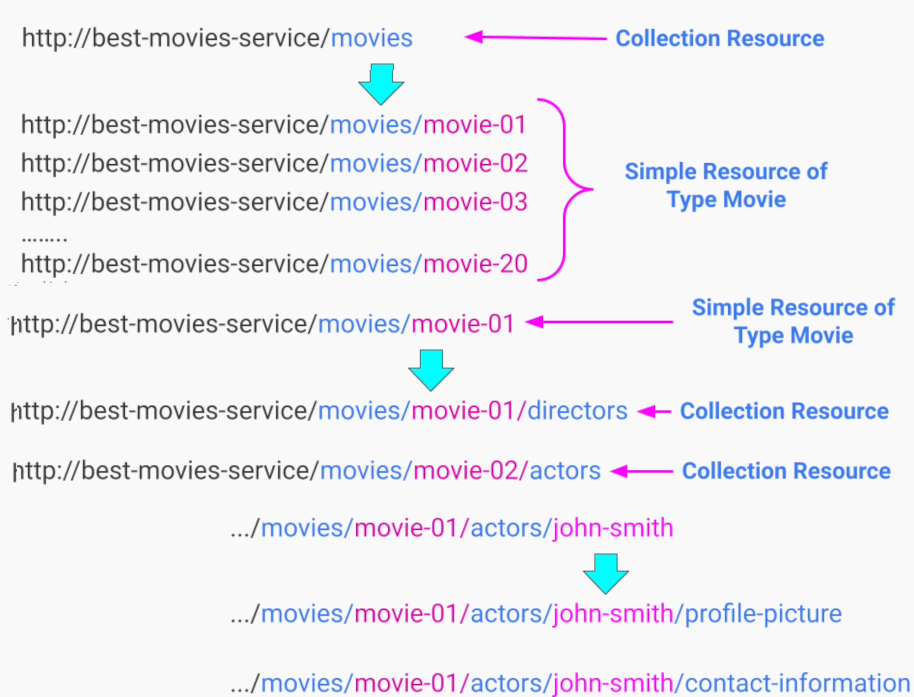
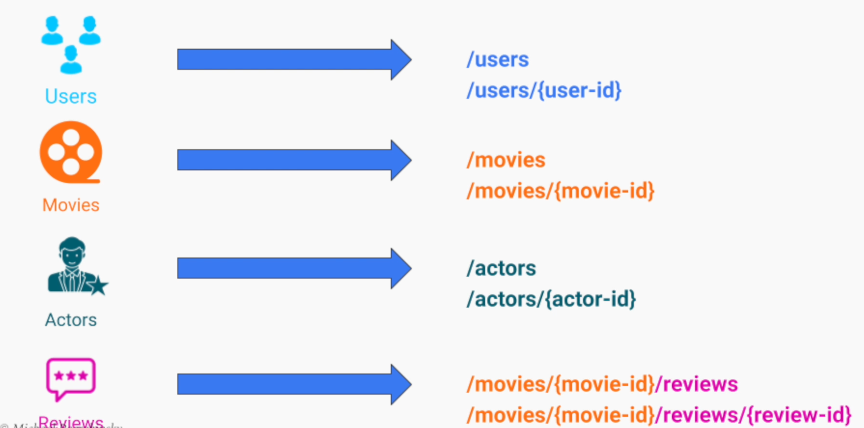
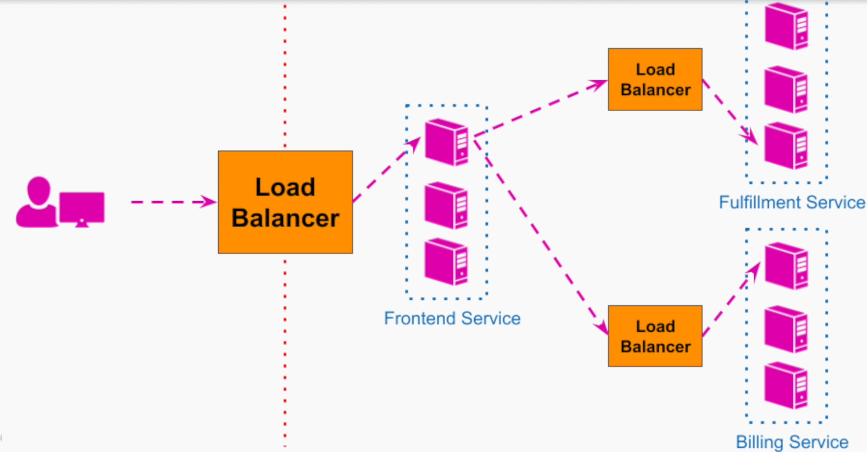
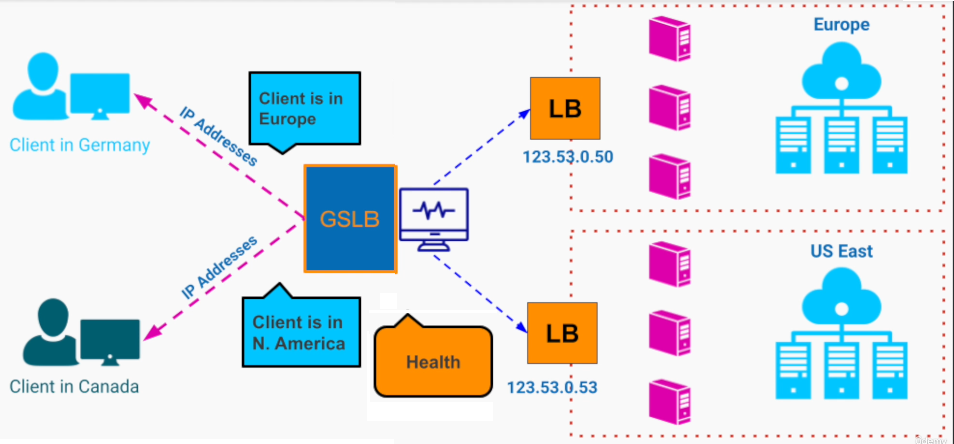
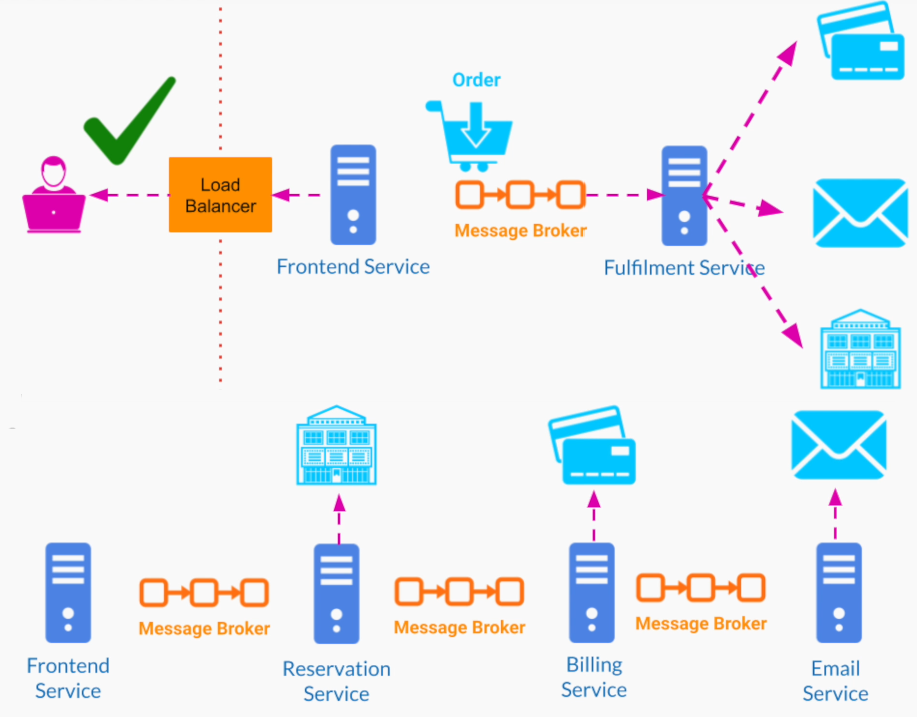
Software Architecture Design Notes
Software Architecture Design
Last Updated: June 01, 2023 by Pepe Sandoval
Want to show support?
If you find the information in this page useful and want to show your support, you can make a donation
Use PayPal
This will help me create more stuff and fix the existent content...